When I worked out how interesting, in an information-theory sense, a basketball game — and from that, a tournament — might be, I supposed there was only one thing that might be interesting about the game: who won? Or to be exact, “did (this team) win”? But that isn’t everything we might want to know about a game. For example, we might want to know what a team scored. People often do. So how to measure this?
The answer was given, in embryo, in my first piece about how interesting a game might be. If you can list all the possible outcomes of something that has multiple outcomes, and how probable each of those outcomes is, then you can describe how much information there is in knowing the result. It’s the sum, for all of the possible results, of the quantity negative one times the probability of the result times the logarithm-base-two of the probability of the result. When we were interested in only whether a team won or lost there were just the two outcomes possible, which made for some fairly simple calculations, and indicates that the information content of a game can be as high as 1 — if the team is equally likely to win or to lose — or as low as 0 — if the team is sure to win, or sure to lose. And the units of this measure are bits, the same kind of thing we use to measure (in groups of bits called bytes) how big a computer file is.
For one team’s score, well, there are many possible outcomes: they might score, for example, 65 points. Or they might score 70 points. They might score 35 points and go on to hide under the bed all weekend. They might score 140 points and spend the weekend explaining why they felt the need to run the score up so awfully high.
And I should warn right now that I am thinking only of how much information there is in finding out one team’s score. Two teams is a more complicated case and I’ll get to that later.
We can work with all the possible outcomes by using the score of the game as an index. If p is our symbol representing the probability of an outcome, then p65 is the probability that in a game the team scores 65 points, no more and no less, while p66 is the probability it scores exactly 66 points. p0 would be the probability that somehow the team fails to score a single point; p400 the probability that somehow the team scores what seems like far too many points to be physically possible, given that the game has a time limit and it’s not like scoring a basket is instantaneous. And so on: pj is the probability that the team scores exactly j points, whatever number j is. If we added together every possible pj for every possible number, we should get 1 — the team is certain to end up with some score — and no pj can be smaller than 0, but at this point we don’t need to know much more about the probabilities, the chances, of any particular score.
In principle, then, the information content for “what has one team scored in this game” would be found by the formula
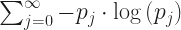
where the 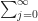

Adding up infinitely many terms would take rather some time. Usually when we need to add infinitely many terms together calculus comes to our rescue and proves that the sum would be between some lower and some upper bound. Often calculus will be even more heroic, and tell us the lower bound and the upper bound are the same number, from which we conclude the sum has to be that number.
If calculus doesn’t tell us what the sum is, we have to fall back on thinking about the problem: is there a plausible reason to believe we don’t need to evaluate infinitely many terms? Can we cut the summation off at some index? This sort of cutoff is common in many problems and it requires having reason to believe that the cutoff terms will be too small to make a difference. For this basketball problem, there certainly is: we know before even going in that so few basketball games will see a score of a million or more points that we will make no discernable error by refusing to consider the possibility. For that matter, we can safely rule out games where one team scores more than 100,000 points.
I do not know what the greatest score ever achieved in college basketball is; I would be surprised if it were more than 200, although I wouldn’t be so sure that, say, 150 couldn’t happen. We will probably be close enough to correct if we simply consider the sum

Of course, this leaves us the problem of working out the probability that a team will finish the game with a score of 0 points, of 1 point, of 2 points, et cetera, up to 200 or whatever our cutoff is. There are some scores that are obviously more probable than others: it’s easy to accept “70” as a team’s score in a game, while “7” or “170” would probably cause people to double-check that they heard that right.
I did try to find an archive of college basketball scores, to see if I could find how often all the various scores turned up in actual games, but my Google skills failed me, possibly because I was using DuckDuckGo, because yeah, I’m that guy. I can’t help it. I like the sincerity implied by DuckDuckGo’s homepage inviting me to set it as my web browser’s default search engine, even though I already have.
Anyway, while surely someone has records of how often each possible score comes up, I couldn’t find it. So I did the next-best thing and made up some numbers. I made the assumption that the distribution of basketball scores — how often 60 turns up, how often 65 does, how often 71 does, et cetera — will be some Gaussian distribution. That’s often a reliable assumption — the Gaussian is also called the “standard” or “standard normal” distribution for a reason — and if I’m wrong, then putting out my calculations based on a wrong idea will inspire someone who knows the correct answer to write in and show me up.
So on the assumption the distribution of college basketball scores is close enough to a standard normal distribution, with an arithmetic mean of 65 (if you added up all the scores and divided by the number of games, it’d be about 65), and a standard deviation of 10 (meaning among other things that a team scores between 45 and 85 in about 95 percent of its games, and between 35 and 95 in about 99 percent of its games), I generated scores for a million simulated games and worked out how often each of the possible scores came up.
In practice, in this million simulated games, scores ranged between 13 and 118, but were most often at or around 65, just as I wanted. From this start the most probable score was 65, although only about four percent of all games had that score exactly, and 64 and 66 and such were not much less likely to turn up.
And based on this, the formula given suggests that one team’s score in a basketball game has an information content of something like 5.37 bits. Call it 5.4 so as not to have too many of those hypnotic digits past the decimal point.
That might sound weird: the mere information of whether a team won is (up to) 1 bit, but their score only a little over 5 bits? But let me justify why this is probably right. Suppose you were trying to find a number between 13 and 118, with every one of those numbers equally likely to be the one you’re searching for, and could only search by asking yes-or-no questions. If you asked a series of questions like “is the number less than 65?” and “is the number more than 39?” and so on, with the answer at each step equally likely to be yes or no, then you could pin down the sought-for number in no more than seven questions. (If you’re not sure about this, watch some contestants playing the Clock Game on The Price Is Right and you’ll get the hang of it.)
So we wouldn’t expect there to be more than 7 bits of information in the score. And some scores are quite unlikely to turn up, such as 13 or 14 or 15. So the information content should be less than that 7 bits. If we supposed the number were somewhere between 35 and 95 — which, 99 percent of the time, it is — that would take not more than six well-chosen questions to pin down; if we supposed the number were between 45 and 85 — as it is 95 percent of the time — then five well-chosen questions would typically be enough to pin it down, with six sometimes needed. This is why I think it plausible that around five-and-a-third bits is the right measure.
I want to close this essay, though not the topic, by pointing out again that I was looking at the information content of one team’s score. There’s normally two teams playing and I haven’t said what I think the information content of both scores is. I hope to get to that in the next essay of this series.

5 thoughts on “But How Interesting Is A Basketball Score?”