Before I get to today’s round of mathematics comics, a legend-or-joke, traditionally starring John Von Neumann as the mathematician.
The recreational word problem goes like this: two bicyclists, twenty miles apart, are pedaling toward each other, each at a steady ten miles an hour. A fly takes off from the first bicyclist, heading straight for the second at fifteen miles per hour (ground speed); when it touches the second bicyclist it instantly turns around and returns to the first at again fifteen miles per hour, at which point it turns around again and head for the second, and back to the first, and so on. By the time the bicyclists reach one another, the fly — having made, incidentally, infinitely many trips between them — has travelled some distance. What is it?
And this is not hard problem to set up, inherently: each leg of the fly’s trip is going to be a certain ratio of the previous leg, which means that formulas for a geometric infinite series can be used. You just need to work out what the lengths of those legs are to start with, and what that ratio is, and then work out the formula in your head. This is a bit tedious and people given the problem may need some time and a couple sheets of paper to make it work.
Von Neumann, who was an expert in pretty much every field of mathematics and a good number of those in physics, allegedly heard the problem and immediately answered: 15 miles! And the problem-giver said, oh, he saw the trick. (Since the bicyclists will spend one hour pedaling before meeting, and the fly is travelling fifteen miles per hour all that time, it travels a total of a fifteen miles. Most people don’t think of that, and try to sum the infinite series instead.) And von Neumann said, “What trick? All I did was sum the infinite series.”
Did this charming story of a mathematician being all mathematicky happen? Wikipedia’s description of the event credits Paul Halmos’s recounting of Nicholas Metropolis’s recounting of the story, which as a source seems only marginally better than “I heard it on the Internet somewhere”. (Other versions of the story give different distances for the bicyclists and different speeds for the fly.) But it’s a wonderful legend and can be linked to a Herb and Jamaal comic strip from this past week.
Paul Trap’s Thatababy (April 29) has the baby “blame entropy”, which fits as a mathematical concept, it seems to me. Entropy as a concept was developed in the mid-19th century as a thermodynamical concept, and it’s one of those rare mathematical constructs which becomes a superstar of pop culture. It’s become something of a fancy word for disorder or chaos or just plain messes, and the notion that the entropy of a system is ever-increasing is probably the only bit of statistical mechanics an average person can be expected to know. (And the situation is more complicated than that; for example, it’s just more probable that the entropy is increasing in time.)
Entropy is a great concept, though, as besides capturing very well an idea that’s almost universally present, it also turns out to be meaningful in surprising new places. The most powerful of those is in information theory, which is just what the label suggests; the field grew out of the problem of making messages understandable even though the telegraph or telephone lines or radio beams on which they were sent would garble the messages some, even if people sent or received the messages perfectly, which they would not. The most captivating (to my mind) new place is in black holes: the event horizon of a black hole has a surface area which is (proportional to) its entropy, and consideration of such things as the conservation of energy and the link between entropy and surface area allow one to understand something of the way black holes ought to interact with matter and with one another, without the mathematics involved being nearly as complicated as I might have imagined a priori.
Meanwhile, Lincoln Pierce’s Big Nate (April 30) mentions how Nate’s Earned Run Average has changed over the course of two innings. Baseball is maybe the archetypical record-keeping statistics-driven sport; Alan Schwarz’s The Numbers Game: Baseball’s Lifelong Fascination With Statistics notes that the keeping of some statistical records were required at least as far back as 1837 (in the Constitution of the Olympic Ball Club of Philadelphia). Earned runs — along with nearly every other baseball statistic the non-stathead has heard of other than batting averages — were developed as a concept by the baseball evangelist and reporter Henry Chadwick, who presented them from 1867 as an attempt to measure the effectiveness of batting and fielding. (The idea of the pitcher as an active player, as opposed to a convenient way to get the ball into play, was still developing.) But — and isn’t this typical? — he would come to oppose the earned run average as a measure of pitching performance, because things that were really outside the pitcher’s control, such as stolen bases, contributed to it.
It seems to me there must be some connection between the record-keeping of baseball and the development of statistics as a concept in the 19th century. Granted the 19th century was a century of statistics, starting with nation-states measuring their populations, their demographics, their economies, and projecting what this would imply for future needs; and then with science, as statistical mechanics found it possible to quite well understand the behavior of millions of particles despite it being impossible to perfectly understand four; and in business, as manufacturing and money were made less individual and more standard. There was plenty to drive the field without an amusing game, but, I can’t help thinking of sports as a gateway into the field.

The Disney Company’s Donald Duck (May 2, rerun) suggests that Ludwig von Drake is continuing to have problems with his computing machine. Indeed, he’s apparently having the same problem yet. I’d like to know when these strips originally ran, but the host site of creators.com doesn’t give any hint.
Stephen Bentley’s Herb and Jamaal (May 3) has the kid whose name I don’t really know fret how he spent “so much time” on an equation which would’ve been easy if he’d used “common sense” instead. But that’s not a rare phenomenon mathematically: it’s quite possible to set up an equation, or a process, or a something which does indeed inevitably get you to a correct answer but which demands a lot of time and effort to finish, when a stroke of insight or recasting of the problem would remove that effort, as in the von Neumann legend. The commenter Dartpaw86, on the Comics Curmudgeon site, brought up another excellent example, from Katie Tiedrich’s Awkward Zombie web comic. (I didn’t use the insight shown in the comic to solve it, but I’m happy to say, I did get it right without going to pages of calculations, whether or not you believe me.)
However, having insights is hard. You can learn many of the tricks people use for different problems, but, say, no amount of studying the Awkward Zombie puzzle about a square inscribed in a circle inscribed in a square inscribed in a circle inscribed in a square will help you in working out the area left behind when a cylindrical tube is drilled out of a sphere. Setting up an approach that will, given enough work, get you a correct solution is worth knowing how to do, especially if you can give the boring part of actually doing the calculations to a computer, which is indefatigable and, certain duck-based operating systems aside, pretty reliable. That doesn’t mean you don’t feel dumb for missing the recasting.

Rick DeTorie’s One Big Happy (May 3) puns a little on the meaning of whole numbers. It might sound a little silly to have a name for only a handful of numbers, but, there’s no reason not to if the group is interesting enough. It’s possible (although I’d be surprised if it were the case) that there are only 47 Mersenne primes (a number, such as 7 or 31, that is one less than a whole power of 2), and we have the concept of the “odd perfect number”, when there might well not be any such thing.



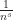 . Then add up all those terms. It’s not explicit here, but context would make clear, n is positive whole numbers: 1, 2, 3, and so on. s would be a positive number, possibly a whole number.
. Then add up all those terms. It’s not explicit here, but context would make clear, n is positive whole numbers: 1, 2, 3, and so on. s would be a positive number, possibly a whole number.  . Then multiply all that together. In the context of the Riemann Zeta function, “p” here isn’t just any old number, or even any old whole number. It’s only the prime numbers. Hence the “p”. Good notation, right? Yeah.
. Then multiply all that together. In the context of the Riemann Zeta function, “p” here isn’t just any old number, or even any old whole number. It’s only the prime numbers. Hence the “p”. Good notation, right? Yeah. 
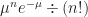 . Here e is that base of the natural logarithm, that 2.71828 et cetera number. n! is the factorial. That’s n times (n – 1) times (n – 2) times (n – 3) and so on all the way down to times 2 times 1.
. Here e is that base of the natural logarithm, that 2.71828 et cetera number. n! is the factorial. That’s n times (n – 1) times (n – 2) times (n – 3) and so on all the way down to times 2 times 1. 










