The joke to which I alluded last week was a quick pun. The setup is, “What is yellow and equivalent to the Axiom of Choice?” It’s the topic for this week, and the conclusion of the Little 2021 Mathematics A-to-Z. I again thank Mr Wu, of Singapore Maths Tuition, for a delightful topic.
Zorn’s Lemma
Max Zorn did not name it Zorn’s Lemma. You expected that. He thought of it just as a Maximal Principle when introducing it in a 1934 presentation and 1935 paper. The word “lemma” connotes that some theorem is a small thing. It usually means it’s used to prove some larger and more interesting theorem. Zorn’s Lemma is one of those small things. With the right background, a rigorous proof is a couple not-too-dense paragraphs. Without the right background? It’s one of those proofs you read the statement of and nod, agreeing, that sounds reasonable.
The lemma is about partially ordered sets. A set’s partially ordered if it has a relationship between pairs of items in it. You will sometimes see a partially ordered set called a “poset”, a term of mathematical art which make me smile too. If we don’t know anything about the ordering relationship we’ll use the ≤ symbol, just like this was ordinary numbers. To be partially ordered, whenever x ≤ y and y ≤ x, we know that x and y must be equal. And the converse: if x = y then x ≤ y and y ≤ x. What makes this partial is that we’re not guaranteed that every x and y relate in some way. It’s a totally ordered set if we’re guaranteed that at least one of x ≤ y and y ≤ x is always true. And then there is such a thing as a well-ordered set. This is a totally ordered set for which every subset (unless it’s empty) has a minimal element.
If we have a couple elements, each of which we can put in some order, then we can create a chain. If x ≤ y and y ≤ z, then we can write x ≤ y ≤ z and we have at least three things all relating to one another. This seems like stuff too basic to notice, if we think too literally about the relationship being “is less than or equal to”. If the relationship is, say, “divides wholly into”, then we get some interesting different chains. Like, 2 divides into 4, which divides into 8, which divides into 24. And 3 divides into 6 which divides into 24. But 2 doesn’t divide into 3, nor 3 into 2. 4 doesn’t divide into 6, nor 6 into either 8 or 4.
So what Zorn’s Lemma says is, if all the chains in a partially ordered set each have an upper bound, then, the partially ordered set has a maximal element. “Maximal element” here means an element that doesn’t have a bigger comparable element. (That is, m is maximal if there’s no other element b for which m ≤ b. It’s possible that m and b can’t be compared, though, the way 6 doesn’t divide 8 and 8 doesn’t divide 6.) This is a little different from a “maximum” . It’s possible for there to be several maximal elements. But if you parse this as “if you can always find a maximum in a string of elements, there’s some maximum element”? And remember there could be many maximums? Then you’re getting the point.
You may also ask how this could be interesting. Zorn’s Lemma is an existence proof. Most existence proofs assure us a thing we thought existed does, but don’t tell us how to find it. This is all right. We tend to rely on an existence proof when we want to talk about some mathematical item but don’t care about fussy things like what it is. It is much the way we might talk about “an odd perfect number N”. We can describe interesting things that follow from having such a number even before we know what value N has.
A classic example, the one you find in any discussion of using Zorn’s Lemma, is about the basis for a vector space. This is like deciding how to give directions to a point in space. But vector spaces include some quite abstract things. One vector space is “the set of all functions you can integrate”. Another is “matrices whose elements are all four-dimensional rotations”. There might be literally infinitely many “directions” to go. How do we know we can find a set of directions that work as well as, for guiding us around a city, the north-south-east-west compass rose does? So there’s the answer. There are other things done all the time, too. A nontrivial ring-with-identity, for example, has to have a maximal ideal. (An ideal is a subset of the ring that’s still a ring.) This is handy to know if you’re working with rings a lot.
The joke in my prologue was built on the claim Zorn’s Lemma is equivalent to the Axiom of Choice. The Axiom of Choice is a piece of set theory that surprised everyone by being independent of the Zermelo-Fraenkel axioms. The Axiom says that, if you have a collection of disjoint nonempty sets, then there must exist at least one set with exactly one element from each of those sets. That is, you can pick one thing out of each of a set of bins. It’s easy to see how this has in common with Zorn’s Lemma being too obvious to imagine proving. That’s the sort of thing that makes a good axiom. Thing about a lemma, though, is we do prove it. That’s how we know it’s a lemma. How can a lemma be equivalent to an axiom?
I’l argue by analogy. In Euclidean geometry one of the axioms is this annoying statement about on which side of a line two other lines that intersect it will meet. If you have this axiom, you can prove some nice results, like, the interior angles of a triangle add up to two right angles. If you decide you’d rather make your axiom that bit about the interior angles adding up? You can go from that to prove the thing about two lines crossing a third line.
So it is here. If you suppose the Axiom of Choice is true, you can get Zorn’s Lemma: you can pick an element in your set, find a chain for which that’s the minimum, and find your maximal element from that. If you make Zorn’s Lemma your axiom? You can use x ≤ y to mean “x is a less desirable element to pick out of this set than is y”. And then you can choose a maximal element out of your set. (It’s a bit more work than that, but it’s that kind of work.)
There’s another theorem, or principle, that’s (with reservations) equivalent to both Zorn’s Lemma and the Axiom of Choice. It’s another piece that seems so obvious it should defy proof. This is the well-ordering theorem, which says that every set can be well-ordered. That is, so that every non-empty subset has some minimum element. Finally, a mathematical excuse for why we have alphabetical order, even if there’s no clear reason that “j” should come after “i”.
(I said “with reservations” above. This is because whether these are equivalent depends on what, precisely, kind of deductive logic you’re using. If you are not using ordinary propositional logic, and are using a “second-order logic” instead, they differ.)
Ermst Zermelo introduced the Axiom of Choice to set theory so that he could prove this in a way that felt reasonable. I bet you can imagine how you’d go from “every non-empty set has a minimum element” right back to “you can always pick one element of every set”, though. And, maybe if you squint, can see how to get from “there’s always a minimum” to “there has to be a maximum”. I’m speaking casually here because proving it precisely is more work than we need to do.
I mentioned how Zorn did not name his lemma after himself. Mathematicians typically don’t name things for themselves. Nor did he even think of it as a lemma. His name seems to have adhered to the principle in the late 30s. Credit the nonexistent mathematician Bourbaki writing about “le théorème de Zorn”. By 1940 John Tukey, celebrated for the Fast Fourier Transform, wrote of “Zorn’s Lemma”. Tukey’s impression was that this is how people in Princeton spoke of it at the time. He seems to have been the first to put the words “Zorn’s Lemma” in print, though. Zorn isn’t the first to have stated this. Kazimierez Kuratowski, in 1922, described what is clearly Zorn’s Lemma in a different form. Zorn remembered being aware of Kuratowski’s publication but did not remember noticing the property. The Hausdorff Maximal Principle, of Felix Hausdorff, has much the same content. Zorn said he did not know about Hausdorff’s 1927 paper until decades later.
Zorn’s lemma, the Axiom of Choice, the well-ordering theorem, and Hausdorff’s Maximal Principle all date to the early 20th century. So do a handful of other ideas that turn out to be equivalent. This was an era when set theory saw an explosive development of new and powerful ideas. The point of describing this chain is to emphasize that great concepts often don’t have a unique presentation. Part of the development of mathematics is picking through several quite similar expressions of a concept. Which one do we enshrine as an axiom, or at least the canonical presentation of the idea?
We have to choose.
And with this I at last declare the hard work Little 2021 Mathematics A-to-Z at an end. I plan to follow up, as traditional, with a little essay about what I learned while doing this project. All of the Little 2021 Mathematics A-to-Z essays should be at this link. And then all of the A-to-Z essays from all eight projects should be at this link. Thank you so for your support in these difficult times.













![A numeral 2 is on the page. Alice, offscreen, asks: 'Petey, what letter is that?' Petey: 'It's the *number* two.' Alice: 'Is it happy or sad?' Petey: 'I don't know.' Alice: 'It's a girl, right? And it's green?' The numeral is now green, has long hair, and a smile. Petey: 'Well --- ' Alice: 'Does she wear a hat? Like a beret?' 'A hat?' The numeral now has a beret. Alice: 'Does she have a pet? I'll give her a few hamsters. Petey: 'A pet?' There are a copule hamsters around the 2 now. Alice: 'She likes *this* number.' Petey: 'Why --- ' The other number is a 5. Alice: 'But not *this* number. [ It's a 9. ] Because he's not looking at her.' The 2 is frowning at the 9. Petey: 'How do you --- ' Alice: 'What kind of music does she listen to?' Petey: 'ALICE! Stop asking me all this stuff! *I'm* no good at math!' Alice, upset: 'So it's up to *me* to be the family genius ... '](https://nebusresearch.files.wordpress.com/2022/07/cul-de-sac_richard-thompson_2022-07july-03.jpeg)
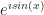 as a pleasant, well-behaved function, but is likely to see
as a pleasant, well-behaved function, but is likely to see 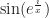 as a troublesome one. These examples all tie to how easy they are to do other stuff with. But it is natural to think fondly of things you see a lot that work nicely for you. These don’t always have to be “nice” things. If you want to test an idea about continuous curves, for example, it’s convenient to have handy the Koch curve. It’s this spiky fractal that’s nothing but corners, and you can use it to see if the idea holds up. Do this enough, and you come to see a reliable partner to your work.
as a troublesome one. These examples all tie to how easy they are to do other stuff with. But it is natural to think fondly of things you see a lot that work nicely for you. These don’t always have to be “nice” things. If you want to test an idea about continuous curves, for example, it’s convenient to have handy the Koch curve. It’s this spiky fractal that’s nothing but corners, and you can use it to see if the idea holds up. Do this enough, and you come to see a reliable partner to your work.










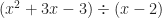 into
into  remainder
remainder 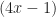 .
. 










 seconds of the universe after the Big Bang. This is an era that was so hot that all our well-tested models of physical law break down. The salient part of the Hartle-Hawking proposal is the idea that in this epoch time becomes indistinguishable from space. If I follow it — do not rely on my understanding for your thesis defense — it’s kind of the way that stepping away from the North Pole first creates the ideas of north and south and east and west. It’s very hard to think of a way to test this which would differentiate it from other hypotheses about the first instances of the universe.
seconds of the universe after the Big Bang. This is an era that was so hot that all our well-tested models of physical law break down. The salient part of the Hartle-Hawking proposal is the idea that in this epoch time becomes indistinguishable from space. If I follow it — do not rely on my understanding for your thesis defense — it’s kind of the way that stepping away from the North Pole first creates the ideas of north and south and east and west. It’s very hard to think of a way to test this which would differentiate it from other hypotheses about the first instances of the universe.


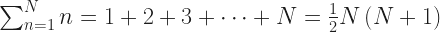




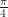 or
or  or
or 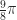 , because these are radian measure rather than degree measure. It’s a different scale, one that’s more convenient for calculus. And for some ordinary uses too: an angle of (say)
, because these are radian measure rather than degree measure. It’s a different scale, one that’s more convenient for calculus. And for some ordinary uses too: an angle of (say) 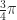 radians sweeps out an arc of length
radians sweeps out an arc of length  on the unit circle. You can see where that’s easier to keep straight than how long an arc of 135 degrees might be.
on the unit circle. You can see where that’s easier to keep straight than how long an arc of 135 degrees might be. 





![[ On the flight to Oregon, Mark Trail is already on a mission ... to learn everything he can about his father's new business partner, Jadsen Sterline! ] Mark Trail: 'Who is this guy and why's he trying to pull the wool over my dad's eyes?' Cherry Trail 'Mark? I snuck you a piece of pie from the airport cafe.' Mark Trail: 'Aw, thank!' [ Today is a good day for pie! ]](https://nebusresearch.files.wordpress.com/2022/03/mark-trail_jules-rivera_2022-march-14.jpg)




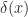 . It’s equal to zero everywhere, except where
. It’s equal to zero everywhere, except where  is zero. When
is zero. When 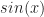 or
or 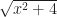 being functions. Many will classify it as a distribution instead. But it is so useful, for a particular kind of problem, that it’s impossible to throw away.
being functions. Many will classify it as a distribution instead. But it is so useful, for a particular kind of problem, that it’s impossible to throw away. 