Charles Merritt sugested a biographical subject for G. (There are often running themes in an A-to-Z and this year’s seems to be “biography”.) I don’t know of a web site or other project that Merritt has that’s worth sharing, but if I learn of it, I’ll pass it along.

J Willard Gibbs.
My love and I, like many people, tried last week to see the comet NEOWISE. It took several attempts. When finally we had binoculars and dark enough sky we still had the challenge of where to look. Finally determined searching and peripheral vision (which is more sensitive to faint objects) found the comet. But how to guide the other to a thing barely visible except with binoculars? Between the silhouettes of trees and a convenient pair of guide stars we were able to put the comet’s approximate location in words. Soon we were experts at finding it. We could turn a head, hold up the binoculars, and see a blue-ish puff of something.
To perceive a thing is not to see it. Astronomy is full of things seen but not recognized as important. There is a great need for people who can describe to us how to see a thing. And this is part of the significance of J Willard Gibbs.
American science, in the 19th century, had an inferiority complex compared to European science. Fairly, to an extent: what great thinkers did the United States have to compare to William Thompson or Joseph Fourier or James Clerk Maxwell? The United States tried to argue that its thinkers were more practical minded, with Joseph Henry as example. Without downplaying Henry’s work, though? The stories of his meeting the great minds of Europe are about how he could fix gear that Michael Faraday could not. There is a genius in this, yes. But we are more impressed by magnetic fields than by any electromagnet.
Gibbs is the era’s exception, a mathematical physicist of rare insight and creativity. In his ability to understand problems, yes. But also in organizing ways to look at problems so others can understand them better. A good comparison is to Richard Feynman, who understood a great variety of problems, and organized them for other people to understand. No one, then or now, doubted Gibbs compared well to the best European minds.
Gibbs’s life story is almost the type case for a quiet academic life. He was born into an academic/ministerial family. Attended Yale. Earned what appears to be the first PhD in engineering granted in the United States, and only the fifth non-honorary PhD in the country. Went to Europe for three years, then came back home, got a position teaching at Yale, and never left again. He was appointed Professor of Mathematical Physics, the first such in the country, at age 32 and before he had even published anything. This speaks of how well-connected his family was. Also that he was well-off enough not to need a salary. He wouldn’t take one until 1880, when Yale offered him two thousand per year against Johns Hopkins’s three.
Between taking his job and taking his salary, Gibbs took time to remake physics. This was in thermodynamics, possibly the most vibrant field of 19th century physics. The wonder and excitement we see in quantum mechanics resided in thermodynamics back then. Though with the difference that people with a lot of money were quite interested in the field’s results. These were people who owned railroads, or factories, or traction companies. Extremely practical fields.
What Gibbs offered was space, particularly, phase space. Phase space describes the state of a system as a point in … space. The evolution of a system is typically a path winding through space. Constraints, like the conservation of energy, we can usually understand as fixing the system to a surface in phase space. Phase space can be as simple as “the positions and momentums of every particle”, and that often is what we use. It doesn’t need to be, though. Gibbs put out diagrams where the coordinates were things like temperature or pressure or entropy or energy. Looking at these can let one understand a thermodynamic system. They use our geometric sense much the same way that charts of high- and low-pressure fronts let one understand the weather. James Clerk Maxwell, famous for electromagnetism, was so taken by this he created plaster models of the described surface.
This is, you might imagine, pretty serious, heady stuff. So you get why Gibbs published it in the Transactions of the Connecticut Academy: his brother-in-law was the editor. It did not give the journal lasting fame. It gave his brother-in-law a heightened typesetting bill, and Yale faculty and New Haven businessmen donated funds.
Which gets to the less-happy parts of Gibbs’s career. (I started out with ‘less pleasant’ but it’s hard to spot an actually unpleasant part of his career.) This work sank without a trace, despite Maxwell’s enthusiasm. It emerged only in the middle of the 20th century, as physicists came to understand their field as an expression of geometry.
That’s all right. Chemists understood the value of Gibbs’s thermodynamics work. He introduced the enthalpy, an important thing that nobody with less than a Master’s degree in Physics feels they understand. Changes of enthalpy describe how heat transfers. And the Gibbs Free Energy, which measures how much reversible work a system can do if the temperature and pressure stay constant. A chemical reaction where the Gibbs free energy is negative will happen spontaneously. If the system’s in equilibrium, the Gibbs free energy won’t change. (I need to say the Gibbs free energy as there’s a different quantity, the Helmholtz free energy, that’s also important but not the same thing.) And, from this, the phase rule. That describes how many independently-controllable variables you can see in mixing substances.
In the 1880s Gibbs worked on something which exploded through physics and mathematics. This was vectors. He didn’t create them from nothing. Hermann Günter Grassmann — whose fascinating and frustrating career I hadn’t known of before this — laid much of the foundation. Building on Grassman and W K Clifford, though, let Gibbs present vectors as we now use them in physics. How to define dot products and cross products. How to use them to simplify physics problems. How they’re less work than quaternions are. Gibbs was not the only person to recast physics in vector form. Oliver Heaviside is another important mathematical physicist of the time who did. But Gibbs identified the tools extremely well. You can read his Elements of Vector Analysis. It’s not very different from what a modern author would write on the subject. It’s terser than I would write, but terse is also respectful of someone’s time and ability to reason out explanations of small points.
There are more pieces. They don’t all fit in a neat linear timeline; nobody’s life really does. Gibbs’s thermodynamics work, leading into statistical mechanics, foreshadows much of quantum mechanics. He’s famous for the Gibbs Paradox, which concerns the entropy of mixing together two different kinds of gas. Why is this different from mixing together two containers of the same kind of gas? And the answer is that we have to think more carefully about what we mean by entropy, and about the differences between containers.
There is a Gibbs phenomenon, known to anyone studying Fourier series. The Fourier series is a sum of sine and cosine functions. It approximates an arbitrary original function. The series is a continuous function; you could draw it without lifting your pen. If the original function has a jump, though? A spot where you have to lift your pen? The Fourier series for that represents the jump with a region where its quite-good approximation suddenly turns bad. It wobbles around the ‘correct’ values near the jump. Using more terms in the series doesn’t make the wobbling shrink. Gibbs described it, in studying sawtooth waves. As it happens, Henry Wilbraham first noticed and described this in 1848. But Wilbraham’s work went unnoticed until after Gibbs’s rediscovery.
And then there was a bit in which Gibbs was intrigued by a comet that prolific comet-spotter Lewis Swift observed in 1880. Finding the orbit of a thing from a handful of observations is one of the great problems of astronomical mathematics. Karl Friedrich Gauss started the 19th century with his work projecting the orbit of the newly-discovered and rapidly-lost asteroid Ceres. Gibbs put his vector notation to the work of calculating orbits. His technique, I am told by people who seem to know, is less difficult and more numerically stable than was earlier used.
Swift’s comet of 1880, it turns out, was spotted in 1869 by Wilhelm Tempel. It was lost after its 1908 perihelion. Comets have a nasty habit of changing their orbits on us. But it was rediscovered in 2001 by the Lincoln Near-Earth Asteroid Research program. It’s next to reach perihelion the 26th of November, 2020. You might get to see this, another thing touched by J Willard Gibbs.
This and the other other A-to-Z topics for 2020 should be at this link. All my essays for this and past A-to-Z sequences are at this link. I’ll soon be opening f or topics for J, K, and L, essays also. Thanks for reading.

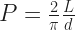
 is raised to the first power, rather than the second or third or such … well, that’s fair. A needle twice as long having twice the chance of crossing a line? That sounds more likely than a needle twice as long having four times the chance, or eight times the chance.
is raised to the first power, rather than the second or third or such … well, that’s fair. A needle twice as long having twice the chance of crossing a line? That sounds more likely than a needle twice as long having four times the chance, or eight times the chance.  , there’s still a probability that the needle crosses at least one line. It never becomes certain. No matter how long the needle is it could fall parallel to all the floor lines and miss them all. The probability is instead:
, there’s still a probability that the needle crosses at least one line. It never becomes certain. No matter how long the needle is it could fall parallel to all the floor lines and miss them all. The probability is instead: 
 is the world-famous arcsecant function. That is, it’s whatever angle has as its secant the number
is the world-famous arcsecant function. That is, it’s whatever angle has as its secant the number 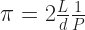



 demonstrates, but it probably came from somewhere. It’s 4,829,210. The exponentials on the blackboard do cue the reader to the real joke, of the sign reading “kick10 me”. I question whether this is really an exponential kicking situation. It seems more like a simple multiplication to me. But it would be harder to make that joke read clearly.
demonstrates, but it probably came from somewhere. It’s 4,829,210. The exponentials on the blackboard do cue the reader to the real joke, of the sign reading “kick10 me”. I question whether this is really an exponential kicking situation. It seems more like a simple multiplication to me. But it would be harder to make that joke read clearly.






 raised to the power of however many characters are in the first script. Call it 800,000 for argument’s sake. More characters, if you put two spaces between sentences. The prospects of getting this all correct is … dismal.
raised to the power of however many characters are in the first script. Call it 800,000 for argument’s sake. More characters, if you put two spaces between sentences. The prospects of getting this all correct is … dismal. 
 (or whatever) of starting the lucky sequence. The monkey will have
(or whatever) of starting the lucky sequence. The monkey will have  chances to start. More chances than that.
chances to start. More chances than that. 


 . That’s a number from 0 to 1. 0 corresponds to not making this mistake; 1 to certainly making it. The chance they get it right is
. That’s a number from 0 to 1. 0 corresponds to not making this mistake; 1 to certainly making it. The chance they get it right is  . The chance they make this mistake twice is smaller than
. The chance they make this mistake twice is smaller than 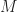 . If the monkeys have taken more than
. If the monkeys have taken more than 








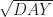 .
. 










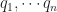 for the (generalized) coördinates,
for the (generalized) coördinates,  for the (generalized) velocities, and
for the (generalized) velocities, and  [1]
[1] the (generalized) forces, and the quantities
the (generalized) forces, and the quantities  , defined by the equations
, defined by the equations 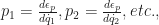 [2]
[2] denotes the kinetic energy of the system, the (generalized) momenta. The kinetic energy is here regarded as a function of the velocities and coördinates. We shall usually regard it as a function of the momenta and coördinates, and on this account we denote it by
denotes the kinetic energy of the system, the (generalized) momenta. The kinetic energy is here regarded as a function of the velocities and coördinates. We shall usually regard it as a function of the momenta and coördinates, and on this account we denote it by  ‘s and
‘s and  ‘s. But in expressions like
‘s. But in expressions like  , where the denominator does not determine the question, the kinetic energy is always to be treated in the differentiation as function of the p’s and q’s.
, where the denominator does not determine the question, the kinetic energy is always to be treated in the differentiation as function of the p’s and q’s. 