As I’ve laid out the tools that the Harvard IBM Automatic Sequence-Controlled Calculator would use to work out a common logarithm, now I can show how this computer of the 1940s and 1950s would do it. The goal, remember, is to compute logarithms to a desired accuracy, using computers that haven’t got abundant memory, and as quickly as possible. As quickly as possible means, roughly, avoiding multiplication (which takes time) and doing as few divisions as can possibly be done (divisions take forever).
As a reminder, the tools we have are:
- We can work out at least some logarithms ahead of time and look them up as needed.
- The natural logarithm of a number close to 1 is
 .
.
- If we know a number’s natural logarithm (base e), then we can get its common logarithm (base 10): multiply the natural logarithm by the common logarithm of e, which is about 0.43429.
- Whether the natural or the common logarithm (or any other logarithm you might like)

Now we’ll put this to work. The first step is which logarithms to work out ahead of time. Since we’re dealing with common logarithms, we only need to be able to work out the logarithms for numbers between 1 and 10: the common logarithm of, say, 47.2286 is one plus the logarithm of 4.72286, and the common logarithm of 0.472286 is minus two plus the logarithm of 4.72286. So we’ll start by working out the logarithms of 1, 2, 3, 4, 5, 6, 7, 8, and 9, and storing them in what, in 1944, was still a pretty tiny block of memory. The original computer using this could store 72 numbers at a time, remember, though to 23 decimal digits.
So let’s say we want to know the logarithm of 47.2286. We have to divide this by 10 in order to get the number 4.72286, which is between 1 and 10, so we’ll need to add one to whatever we get for the logarithm of 4.72286 is. (And, yes, we want to avoid doing divisions, but dividing by 10 is a special case. The Automatic Sequence-Controlled Calculator stored numbers, if I am not grossly misunderstanding things, in base ten, and so dividing or multiplying by ten was as fast for it as moving the decimal point is for us. Modern computers, using binary arithmetic, find it as fast to divide or multiply by powers of two, even though division in general is a relatively sluggish thing.)
We haven’t worked out what the logarithm of 4.72286 is. And we don’t have a formula that’s good for that. But: 4.72286 is equal to 4 times 1.1807, and therefore the logarithm of 4.72286 is going to be the logarithm of 4 plus the logarithm of 1.1807. We worked out the logarithm of 4 ahead of time (it’s about 0.60206, if you’re curious).
We can use the infinite series formula to get the natural logarithm of 1.1807 to as many digits as we like. The natural logarithm of 1.1807 will be about  or 0.16613. Multiply this by the logarithm of e (about 0.43429) and we have a common logarithm of about 0.07214. (We have an error estimate, too: we’ve got the natural logarithm of 1.1807 within a margin of error of
or 0.16613. Multiply this by the logarithm of e (about 0.43429) and we have a common logarithm of about 0.07214. (We have an error estimate, too: we’ve got the natural logarithm of 1.1807 within a margin of error of  , or about 0.000 0058, which, multiplied by the logarithm of e, corresponds to a margin of error for the common logarithm of about 0.000 0025.
, or about 0.000 0058, which, multiplied by the logarithm of e, corresponds to a margin of error for the common logarithm of about 0.000 0025.
Therefore: the logarithm of 47.2286 is about 1 plus 0.60206 plus 0.07214, which is 1.6742. And it is, too; we’ve done very well at getting the number just right considering how little work we really did.
Although … that infinite series formula. That requires a fair number of multiplications, at least eight as I figure it, however you look at it, and those are sluggish. It also properly speaking requires divisions, although you could easily write your code so that instead of dividing by 4 (say) you multiply by 0.25 instead. For this particular example number of 47.2286 we didn’t need very many terms in the series to get four decimal digits of accuracy, but maybe we got lucky and some other number would have required dozens of multiplications. Can we make this process, on average, faster?
And here’s one way to do it. Besides working out the common logarithms for the whole numbers 1 through 9, also work out the common logarithms for 1.1, 1.2, 1.3, 1.4, et cetera up to 1.9. And then …
We started with 47.2286. Divide by 10 (a free bit of work) and we have 4.72286. Divide 4.72286 is 4 times 1.180715. And 1.180715 is equal to 1.1 — the whole number and the first digit past the decimal — times 1.07337. That is, 47.2286 is 10 times 4 times 1.1 times 1.07337. And so the logarithm of 47.2286 is the logarithm of 10 plus the logarithm of 4 plus the logarithm of 1.1 plus the logarithm of 1.07337. We are almost certainly going to need fewer terms in the infinite series to get the logarithm of 1.07337 than we need for 1.180715 and so, at the cost of one more division, we probably save a good number of multiplications.
The common logarithm of 1.1 is about 0.041393. So the logarithm of 10 (1) plus the logarithm of 4 (0.60206) plus the logarithm of 1.1 (0.041393) is 1.6435, which falls a little short of the actual logarithm we’d wanted, about 1.6742, but two or three terms in the infinite series should be enough to make that up.
Or we could work out a few more common logarithms ahead of time: those for 1.01, 1.02, 1.03, and so on up to Our original 47.2286 divided by 10 is 4.72286. Divide that by the first number, 4, and you get 1.180715. Divide 1.180715 by 1.1, the first two digits, and you get 1.07337. Divide 1.07337 by 1.07, the first three digits, and you get 1.003156. So 47.2286 is 10 times 4 times 1.1 times 1.07 times 1.003156. So the common logarithm of 47.2286 is the logarithm of 10 (1) plus the logarithm of 4 (0.60206) plus the logarithm of 1.1 (0.041393) plus the logarithm of 1.07 (about 0.02938) plus the logarithm of 1.003156 (to be determined). Even ignoring the to-be-determined part that adds up to 1.6728, which is a little short of the 1.6742 we want but is doing pretty good considering we’ve reduced the whole problem to three divisions, looking stuff up, and four additions.
If we go a tiny bit farther, and also have worked out ahead of time the logarithms for 1.001, 1.002, 1.003, and so on out to 1.009, and do the same process all over again, then we get some better accuracy and quite cheaply yet: 47.2286 divided by 10 is 4.72286. 4.72286 divided by 4 is 1.180715. 1.180715 divided by 1.1 is 1.07337. 1.07337 divided by 1.07 is 1.003156. 1.003156 divided by 1.003 is 1.0001558.
So the logarithm of 47.2286 is the logarithm of 10 (1) plus the logarithm of 4 (0.60206) plus the logarithm of 1.1 (0.041393) plus the logarithm of 1.07 (0.029383) plus the logarithm of 1.003 (0.001301) plus the logarithm of 1.001558 (to be determined). Leaving aside the to-be-determined part, that adds up to 1.6741.
And the to-be-determined part is great: if we used just a single term in this series, the margin for error would be, at most, 0.000 000 0052, which is probably small enough for practical purposes. The first term in the to-be-determined part is awfully easy to calculate, too: it’s just 1.0001558 – 1, that is, 0.0001558. Add that and we have an approximate logarithm of 1.6742, which is dead on.
And I do mean dead on: work out more decimal places of the logarithm based on this summation and you get 1.674 205 077 226 78. That’s no more than five billionths away from the correct logarithm for the original 47.2286. And it required doing four divisions, one multiplication, and five additions. It’s difficult to picture getting such good precision with less work.
Of course, that’s done in part by having stockpiled a lot of hard work ahead of time: we need to know the logarithms of 1, 1.1, 1.01, 1.001, and then 2, 1.2, 1.02, 1.002, and so on. That’s 36 numbers altogether and there are many ways to work out logarithms. But people have already done that work, and we can use that work to make the problems we want to do considerably easier.
But there’s the process. Work out ahead of time logarithms for 1, 1.1, 1.01, 1.001, and so on, to whatever the limits of your patience. Then take the number whose logarithm you want and divide (or multiply) by ten until you get your working number into the range of 1 through 10. Divide out the first digit, which will be a whole number from 1 through 9. Divide out the first two digits, which will be something from 1.1 to 1.9. Divide out the first three digits, something from 1.01 to 1.09. Divide out the first four digits, something from 1.001 to 1.009. And so on. Then add up the logarithms of the power of ten you divided or multiplied by with the logarithm of the first divisor and the second divisor and third divisor and fourth divisor, until you run out of divisors. And then — if you haven’t already got the answer as accurately as you need — work out as many terms in the infinite series as you need; probably, it won’t be very many. Add that to your total. And you are, amazingly, done.


 — of milk.
— of milk.  . It, too, is between 0 and 1. After this, I refill the mug up to full, so, putting in
. It, too, is between 0 and 1. After this, I refill the mug up to full, so, putting in  times.
times.  . I could be more precise by refilling the mug
. I could be more precise by refilling the mug  times. I’m also going to suppose that I refill the mug with
times. I’m also going to suppose that I refill the mug with 
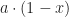 units of milk in the mixture.
units of milk in the mixture.  milk in the mixture.
milk in the mixture.  . And are pretty sure what happens at the fourth and fifth and so on. If you didn’t nod to that, it’s all right. If you’re willing to take me on faith we can continue. If you’re not, that’s good too. Try doing a couple drawings yourself and you may convince yourself. If not, I don’t know. Maybe try, like, getting six white and 24 brown beads, stir them up, take out four at random. Replace all four with brown beads and count, and do that several times over. If you’re short on beads, cut up some paper into squares and write ‘B’ and ‘W’ on each square.
. And are pretty sure what happens at the fourth and fifth and so on. If you didn’t nod to that, it’s all right. If you’re willing to take me on faith we can continue. If you’re not, that’s good too. Try doing a couple drawings yourself and you may convince yourself. If not, I don’t know. Maybe try, like, getting six white and 24 brown beads, stir them up, take out four at random. Replace all four with brown beads and count, and do that several times over. If you’re short on beads, cut up some paper into squares and write ‘B’ and ‘W’ on each square. 
 refills. So my last full mug of tea will have left in it
refills. So my last full mug of tea will have left in it 
 of milk. That’s
of milk. That’s 

 . Everyone knows what that is. But then look at the denominator. In this case, that’s the ‘3’. Why couldn’t that be a sum, instead? No reason. Imagine then the number
. Everyone knows what that is. But then look at the denominator. In this case, that’s the ‘3’. Why couldn’t that be a sum, instead? No reason. Imagine then the number 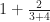 . Is there a reason that we couldn’t, instead of the ‘4’ there, have a fraction instead? No reason beyond our own timidity. Let’s be courageous. Does
. Is there a reason that we couldn’t, instead of the ‘4’ there, have a fraction instead? No reason beyond our own timidity. Let’s be courageous. Does 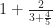 even mean anything?
even mean anything?  is a fine enough number. It’s 3.8.
is a fine enough number. It’s 3.8.  is a less friendly number, but it’s a number anyway. It’s a little over 0.526. (It takes a fair number of digits past the decimal before it ends, but trust me, it does.) And we can add 1 to that easily. So
is a less friendly number, but it’s a number anyway. It’s a little over 0.526. (It takes a fair number of digits past the decimal before it ends, but trust me, it does.) And we can add 1 to that easily. So 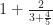 . But after that the LaTeX engine that WordPress uses to render mathematical symbols is doomed. A real LaTeX engine gets another couple nested denominators in before the situation is hopeless. If you’re writing this out on paper, the way people did in the 19th century, that’s all right. But there’s no typing it out that way.
. But after that the LaTeX engine that WordPress uses to render mathematical symbols is doomed. A real LaTeX engine gets another couple nested denominators in before the situation is hopeless. If you’re writing this out on paper, the way people did in the 19th century, that’s all right. But there’s no typing it out that way. 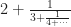 as [2; 3, 4, … ]. The numbers are the whole numbers added to the next level of fractions. Another option, and one that lends itself to having numerators which aren’t 1, is to write out a string of fractions. In this we’d write
as [2; 3, 4, … ]. The numbers are the whole numbers added to the next level of fractions. Another option, and one that lends itself to having numerators which aren’t 1, is to write out a string of fractions. In this we’d write 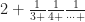 . We have to trust people notice the + sign is in the denominator there. But if people know we’re doing continued fractions then they know to look for the peculiar notation.
. We have to trust people notice the + sign is in the denominator there. But if people know we’re doing continued fractions then they know to look for the peculiar notation. 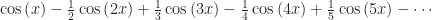 et cetera. There’s one step in it — “integration by parts” — that you’ll have to remember from freshman calculus, or maybe I’ll get around to explaining that someday, but I would expect most folks reading this far could follow this neat result.
et cetera. There’s one step in it — “integration by parts” — that you’ll have to remember from freshman calculus, or maybe I’ll get around to explaining that someday, but I would expect most folks reading this far could follow this neat result.  ? And if you can work that out, what about the number
? And if you can work that out, what about the number  ?
? 
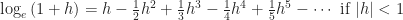
 which is approximately 0.40729. If we were to work out the next term in the series, that would be
which is approximately 0.40729. If we were to work out the next term in the series, that would be  , which has an absolute value of about 0.0026. So the natural logarithm of 1.5 is 0.40729, plus or minus 0.0026. If we only need the natural logarithm to within 0.0026, that’s good: we’re done.
, which has an absolute value of about 0.0026. So the natural logarithm of 1.5 is 0.40729, plus or minus 0.0026. If we only need the natural logarithm to within 0.0026, that’s good: we’re done. 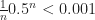 ; if I'm not mistaken, that's eight. Just how many terms we have to calculate will depend on what h is; the bigger it is — the farther the number is from 1 — the more terms we'll need.
; if I'm not mistaken, that's eight. Just how many terms we have to calculate will depend on what h is; the bigger it is — the farther the number is from 1 — the more terms we'll need. 
 . That is, it’s not a difficult thing to write about, but it’s hard to find the audience for this number. It’s quite important, mathematically, but it hasn’t got an easy-to-understand definition like pi’s “the circumference of a circle divided by its diameter”. E’s most concise definition, I guess, is “the base of the natural logarithm”, which as an explanation to someone who hasn’t done much mathematics is only marginally more enlightening than slapping him with a slice of cold pizza. And it hasn’t got the sort of renown of something like the golden ratio which makes the number sound familiar and even welcoming.
. That is, it’s not a difficult thing to write about, but it’s hard to find the audience for this number. It’s quite important, mathematically, but it hasn’t got an easy-to-understand definition like pi’s “the circumference of a circle divided by its diameter”. E’s most concise definition, I guess, is “the base of the natural logarithm”, which as an explanation to someone who hasn’t done much mathematics is only marginally more enlightening than slapping him with a slice of cold pizza. And it hasn’t got the sort of renown of something like the golden ratio which makes the number sound familiar and even welcoming. 

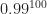 . That takes a little thought to work out if you haven’t got a calculator on hand.
. That takes a little thought to work out if you haven’t got a calculator on hand. 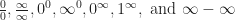 but I would not recommend trusting my memory in favor of actually studying for your test.)
but I would not recommend trusting my memory in favor of actually studying for your test.) 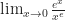
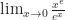
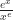 and
and 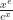 and get a feeling for what the limit probably is. Saying what it definitely is takes a little more work.
and get a feeling for what the limit probably is. Saying what it definitely is takes a little more work. 