I’m still curious about the information-theory content, the entropy, of sports scores. I haven’t found the statistics I need about baseball or soccer game outcomes that I need. I’d also like hockey score outcomes if I could get them. If anyone knows a reference I’d be glad to know of it.
But there’s still stuff I can talk about without knowing details of every game ever. One of them suggested itself when I looked at the Washington Post‘s graphic. I mean the one giving how many times each score came up in baseball’s history.
I had planned to write about this when one of my Twitter friends wrote —
By “distribution” mathematicians mean almost what you would imagine. Suppose we have something that might hold any of a range of values. This we call a “random variable”. How likely is it to hold any particular value? That’s what the distribution tells us. The higher the distribution, the more likely it is we’ll see that value. In baseball terms, that means we’re reasonably likely to see a game with a team scoring three runs. We’re not likely to see a game with a team scoring twenty runs.

There are many families of distributions. Feloni Mayhem suggested the baseball scores look like one called the Beta Distribution. I can’t quite agree, on technical grounds. Beta Distributions describe continuously-valued variables. They’re good for stuff like the time it takes to do something, or the height of a person, or the weight of a produced thing. They’re for measurements that can, in principle, go on forever after the decimal point. A baseball score isn’t like that. A team can score zero points, or one, or 46, but it can’t score four and two-thirds points. Baseball scores are “discrete” variables.
But there are good distributions for discrete variables. Almost everything you encounter taking an Intro to Probability class will be about discrete variables. So will most any recreational mathematics puzzle. The distribution of a tossed die’s outcomes is discrete. So is the number of times tails comes up in a set number of coin tosses. So are the birth dates of people in a room, or the number of cars passed on the side of the road during your ride, or the number of runs scored by a baseball team in a full game.
I suspected that, of the simpler distributions, the best model for baseball should be the Poisson distribution. It also seems good for any other low-scoring game, such as soccer or hockey. The Poisson distribution turns up whenever you have a large number of times that some discrete event can happen. But that event can happen only once each chance. And it has a constant chance of happening. That is, happening this chance doesn’t make it more likely or less likely it’ll happen next chance.
I have reasons to think baseball scoring should be well-modelled this way. There are hundreds of pitches in a game. Each of them is in principle a scoring opportunity. (Well, an intentional walk takes three pitches without offering any chance for scoring. And there’s probably some other odd case where a pitched ball can’t even in principle let someone score. But these are minor fallings-away from the ideal.) This is part of the appeal of baseball, at least for some: the chance is always there.
We only need one number to work out the Poisson distribution of something. That number is the mean, the arithmetic mean of all the possible values. Let me call the mean μ, which is the Greek version of m and so a good name for a mean. The probability that you’ll see the thing happen n times is 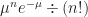
And here is the Poisson distribution for getting numbers from 0 through 20, if we take the mean to be 3.4. I can defend using the Poisson distribution much more than I can defend picking 3.4 as the mean. Why not 3.2, or 3.8? Mostly, I tried a couple means around the three-to-four runs range and picked one that looked about right. Given the lack of better data, what else can I do?

I don’t think it’s a bad fit. The shape looks about right, to me. But the Poisson distribution suggests fewer zero- and one-run games than the actual data offers. And there are more high-scoring games in the real data than in the Poisson distribution. Maybe there’s something that needs tweaking.
And there are several plausible causes for this. A Poisson distribution, for example, supposes that there are a lot of chances for a distinct event. That would be scoring on a pitch. But in an actual baseball game there might be up to four runs scored on one pitch. It’s less likely to score four runs than to score one, sure, but it does happen. This I imagine boosts the number of high-scoring games.
I suspect this could be salvaged by a model that’s kind of a chain of Poisson distributions. That is, have one distribution that represents the chance of scoring on any given pitch. Then use another distribution to say whether the scoring was one, two, three, or four runs.
Low-scoring games I have a harder time accounting for. My suspicion is that each pitch isn’t quite an independent event. Experience shows that pitchers lose control of their game the more they pitch. This results in the modern close watching of pitch counts. We see pitchers replaced at something like a hundred pitches even if they haven’t lost control of the game yet.
If we ignore reasons to doubt this distribution, then, it suggests an entropy of about 2.9 for a single team’s score. That’s lower than the 3.5 bits I estimated last time, using score frequencies. I think that’s because of the multiple-runs problem. Scores are spread out across more values than the Poisson distribution suggests.
If I am right this says we might model games like soccer and hockey, with many chances to score a single run each, with a Poisson distribution. A game like baseball, or basketball, with many chances to score one or more points at once needs a more complicated model.

3 thoughts on “How Interesting Is A Low-Scoring Game?”