Today’s A To Z term is another proposed by @aajohannas.
I couldn’t find a place to fit this in the essay proper. But it’s too good to leave out. The simplex method, discussed within, traces to George Dantzig. He’d been planning methods for the US Army Air Force during the Second World War. Dantzig is a person you have heard about, if you’ve heard any mathematical urban legends. In 1939 he was late to Jerzy Neyman’s class. He took two statistics problems on the board to be homework. He found them “harder than usual”, but solved them in a couple days and turned in the late homework hoping Neyman would be understanding. They weren’t homework. They were examples of famously unsolved problems. Within weeks Neyman had written one of the solutions up for publication. When he needed a thesis topic Neyman advised him to just put what he already had in a binder. It’s the stuff every grad student dreams of. The story mutated. It picked up some glurge to become a narrative about positive thinking. And mutated further, into the movie Good Will Hunting.
The story gets better, for my purposes. The simplex method can be understood as one of those homework problems. Dantzig describes some of that in this 1987 essay about the origins of the method. The essay is worth reading to understand some of how people come to think of good mathematics.

Linear Programming.
Every three days one of the comic strips I read has the elderly main character talk about how they never used algebra. This is my hyperbole. But mathematics has got the reputation for being difficult and inapplicable to everyday life. We’ll concede using arithmetic, when we get angry at the fast food cashier who hands back our two pennies before giving change for our $6.77 hummus wrap. But otherwise, who knows what an elliptic integral is, and whether it’s working properly?
Linear programming does not have this problem. In part, this is because it lacks a reputation. But those who have heard of it, acknowledge it as immensely practical mathematics. It is about something a particular kind of human always finds compelling. That is how to do a thing best.
There are several kinds of “best”. There is doing a thing in as little time as possible. Or for as little effort as possible. For the greatest profit. For the highest capacity. For the best score. For the least risk. The goals have a thousand names, none of which we need to know. They all mean the same thing. They mean “the thing we wish to optimize”. To optimize has two directions, which are one. The optimum is either the maximum or the minimum. To be good at finding a maximum is to be good at finding a minimum.
It’s obvious why we call this “programming”; obviously, we leave the work of finding answers to a computer. It’s a spurious reason. The “programming” here comes from an independent sense of the word. It means more about finding a plan. Think of “programming” a night’s entertainment, so that every performer gets their turn, all scene changes have time to be done, you don’t put two comedians right after the other, and you accommodate the performer who has to leave early and the performer who’ll get in an hour late. Linear programming problems are often about finding how to do as well as possible given various priorities. All right. At least the “linear” part is obvious. A mathematics problem is “linear” when it’s something we can reasonably expect to solve. This is not the technical meaning. Technically what it means is we’re looking at a function something like:
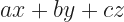
Here, x, y, and z are the independent variables. We don’t know their values but wish to. a, b, and c are coefficients. These values are set to some constant for the problem, but they might be something else for other problems. They’re allowed to be positive or negative or even zero. If a coefficient is zero, then the matching variable doesn’t affect matters at all. The corresponding value can be anything at all, within the constraints.
I’ve written this for three variables, as an example and because ‘x’ and ‘y’ and ‘z’ are comfortable, familiar variables. There can be fewer. There can be more. There almost always are. Two- and three-variable problems will teach you how to do this kind of problem. They’re too simple to be interesting, usually. To avoid committing to a particular number of variables we can use indices. 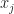

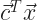
(The superscript T means “transpose”. As a linear algebra problem we’d usually think of writing a vector as a tall column of things. By transposing that we write a long row of things. By transposing we can use the notation of matrix multiplication.)
This is the objective function. Objective here in the sense of goal; it’s the thing we want to find the best possible value of.
We have constraints. These represent limits on the variables. The variables are always things that come in limited supply. There’s no allocating more money than the budget allows, nor putting more people on staff than work for the company. Often these constraints interact. Perhaps not only is there only so much staff, but no one person can work more than a set number of days in a row. Something like that. That’s all right. We can write all these constraints as a matrix equation. An inequality, properly. We can bundle all the constraints into a big matrix named A, and demand:
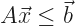
Also, traditionally, we suppose that every component of
But we need some bounds. This is easiest to see with a two-dimensional problem. Try it yourself: draw a pair of axes on a sheet of paper. Now put in a constraint. Doesn’t matter what. The constraint’s edge is a straight line, which you can draw at any position and any angle you like. This includes horizontal and vertical. Shade in one side of the constraint. Whatever you shade in is the “feasible region”, the sets of values allowed under the constraint. Now draw in another line, another constraint. Shade in one side or the other of that. Draw in yet another line, another constraint. Shade in one side or another of that. The “feasible region” is whatever points have taken on all these shades. If you were lucky, this is a bounded region, a triangle. If you weren’t lucky, it’s not bounded. It’s maybe got some corners but goes off to the edge of the page where you stopped shading things in.
So adding that every component of
I didn’t see the bounds you drew. It’s possible you have a triangle with all three shades inside. But it’s also possible you picked the other sides to shade, and you have an annulus, with no region having more than two shades in it. This can happen. It means it’s impossible to satisfy all the constraints at once. At least one of them has to give. You may be reminded of the sign taped to the wall of your mechanics’ about picking two of good-fast-cheap.
But impossibility is at least easy. What if there is a feasible region?
Well, we have reason to hope. The optimum has to be somewhere inside the region, that’s clear enough. And it even has to be on the edge of the region. If you’re not seeing why, think of a simple example, like, finding the maximum of 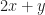
(This doesn’t prove the case. But it is what the proof gets at.)
So the problem sounds simple then! We just have to try out all the vertices and pick the maximum (or minimum) from them all.
OK, and here’s where we start getting into trouble. With two variables and, like, three constraints? That’s easy enough. That’s like five points to evaluate? We can do that.
We never need to do that. If someone’s hiring you to test five combinations I admire your hustle and need you to start getting me consulting work. A real problem will have many variables and many constraints. The feasible region will most often look like a multifaceted gemstone. It’ll extend into more than three dimensions, usually. It’s all right if you just imagine the three, as long as the gemstone is complicated enough.
Because now we’ve got lots of vertices. Maybe more than we really want to deal with. So what’s there to do?
The basic approach, the one that’s foundational to the field, is the simplex method. A “simplex” is a triangle. In three dimensions, anyway. In four dimensions it’s a tetrahedron. In two dimensions it’s a line segment. Generally, however many dimensions of space you have? The simplex is the simplest thing that fills up volume in your space.
You know how you can turn any polygon into a bunch of triangles? Just by connecting enough vertices together? You can turn a polyhedron into a bunch of tetrahedrons, by adding faces that connect trios of vertices. And for polyhedron-like shapes in more dimensions? We call those polytopes. Polytopes we can turn into a bunch of simplexes. So this is why it’s the “simplex method”. Any one simplex it’s easy to check the vertices on. And we can turn the polytope into a bunch of simplexes. And we can ignore all the interior vertices of the simplexes.
So here’s the simplex method. First, break your polytope up into simplexes. Next, pick any simplex; doesn’t matter which. Pick any outside vertex of that simplex. This is the first viable possible solution. It’s most likely wrong. That’s okay. We’ll make it better.
Because there are other vertices on this simplex. And there are other simplexes, adjacent to that first, which share this vertex. Test the vertices that share an edge with this one. Is there one that improves the objective function? Probably. Is there a best one of those in this simplex? Sure. So now that’s our second viable possible solution. If we had to give an answer right now, that would be our best guess.
But this new vertex, this new tentative solution? It shares edges with other vertices, across several simplexes. So look at these new neighbors. Are any of them an improvement? Which one of them is the best improvement? Move over there. That’s our next tentative solution.
You see where this is going. Keep at this. Eventually it’ll wind to a conclusion. Usually this works great. If you have, like, 8 constraints, you can usually expect to get your answer in from 16 to 24 iterations. If you have 20 constraints, expect an answer in from 40 to 60 iterations. This is doing pretty well.
But it might take a while. It’s possible for the method to “stall” a while, often because one or more of the variables is at its constraint boundary. Or the division of polytope into simplexes got unlucky, and it’s hard to get to better solutions. Or there might be a string of vertices that are all at, or near, the same value, so the simplex method can’t resolve where to “go” next. In the worst possible case, the simplex method takes a number of iterations that grows exponentially with the number of constraints. This, yes, is very bad. It doesn’t typically happen. It’s a numerical algorithm. There’s some problem to spoil any numerical algorithm.
You may have complaints. Like, the world is complicated. Why are we only looking at linear objective functions? Or, why only look at linear constraints? Well, if you really need to do that? Go ahead, but that’s not linear programming anymore. Think hard about whether you really need that, though. Linear anything is usually simpler than nonlinear anything. I mean, if your optimization function absolutely has to have 
Maybe you have, and there’s just nothing for it. That’s all right. This is why optimization is a living field of study. It demands judgement and thought and all that hard work.
Thank you for reading. This and all the other Fall 2019 A To Z posts should be at this link. They should be joined next week by letters ‘M’ and ‘N’. Also next week I hope to open for nominations for the next set of letters. All of my past A To Z essays should be available at this link.

11 thoughts on “My 2019 Mathematics A To Z: Linear Programming”