Today’s A To Z term is … well, my second choice. Goldenoj suggested Yang-Mills and I was so interested. Yang-Mills describes a class of mathematical structures. They particularly offer insight into how to do quantum mechanics. Especially particle physics. It’s of great importance. But, on thinking out what I would have to explain I realized I couldn’t write a coherent essay about it. Getting to what the theory is made of would take explaining a bunch of complicated mathematical structures. If I’d scheduled the A-to-Z differently, setting up matters like Lie algebras, maybe I could do it, but this time around? No such help. And I don’t feel comfortable enough in my knowledge of Yang-Mills to describe it without describing its technical points.
That said I hope that Jacob Siehler, who suggested the Game of ‘Y’, does not feel slighted. I hadn’t known anything of the game going in to the essay-writing. When I started research I was delighted. I have yet to actually play a for-real game of this. But I like what I see, and what I can think I can write about it.

Game of ‘Y’.
This is, as the name implies, a game. It has two players. They have the same objective: to create a ‘y’. Here, they do it by laying down tokens representing their side. They take turns, each laying down one token in a turn. They do this on a shape with three edges. The ‘y’ is created when there’s a continuous path of their tokens that reaches all three edges. Yes, it counts to have just a single line running along one edge of the board. This makes a pretty sorry ‘y’ but it suggests your opponent isn’t trying.
There are details of implementation. The board is a mesh of, mostly, hexagons. I take this to be for the same reason that so many conquest-type strategy games use hexagons. They tile space well, they give every space a good number of neighbors, and the distance from the centers of one neighbor to another is constant. In a square grid, the centers of diagonal neighbors are farther than the centers of left-right or up-down neighbors. Hexagons do well for this kind of game, where the goal is to fill space, or at least fill paths in space. There’s even a game named Hex, slightly older than Y, with similar rules. In that the goal is to draw a continuous path from one end of the rectangular grid to another. The grid of commercial boards, that I see, are around nine hexagons on a side. This probably reflects a desire to have a big enough board that games go on a while, but not so big that they go on forever
Mathematicians have things to say about this game. It fits nicely in game theory. It’s well-designed to show some things about game theory. It’s the kind of game which has perfect information game, for example. Each player knows, at all times, the moves all the players have made. Just look at the board and see where they’ve placed their tokens. A player might have forgotten the order the tokens were placed in, but that’s the player’s problem, not the game’s. Anyway in Y, the order of token-placing doesn’t much matter.
It’s also a game of complete information. Every player knows, at every step, what the other player could do. And what objective they’re working towards. One party, thinking enough, could forecast the other’s entire game. This comes close to the joke about the prisoners telling each other jokes by shouting numbers out to one another.
It is also a game in which a draw is impossible. Play long enough and someone must win. This even if both parties are for some reason trying to lose. There are ingenious proofs of this, but we can show it by considering a really simple game. Imagine playing Y on a tiny board, one that’s just one hex on each side. Definitely want to be the first player there.
So now imagine playing a slightly bigger board. Augment this one-by-one-by-one board by one row. That is, here, add two hexes along one of the sides of the original board. So there’s two pieces here; one is the original territory, and one is this one-row augmented territory. Look first at the original territory. Suppose that one of the players has gotten a ‘Y’ for the original territory. Will that player win the full-size board? … Well, sure. The other player can put a token down on either hex in the augmented territory. But there’s two hexes, either of which would make a path that connects the three edges of the board. The first player can put a token down on the other hex in the augmented territory, and now connects all three of the new sides again. First player wins.
All right, but how about a slightly bigger board? So take that two-by-two-by-two board and augment it, adding three hexes along one of the sides. Imagine a player’s won the original territory board. Do they have to win the full-size board? … Sure. The second player can put something in the augmented territory. But there’s again two hexes that would make the path connecting all three sides of the full board. The second player can put a token in one of those hexes. But the first player can put a token in the other of those. First player wins again.
How about a slightly bigger board yet? … Same logic holds. Really the only reason that the first player doesn’t always win is that, at some point, the first player screws up. And this is an existence proof, showing that the first player can always win. It doesn’t give any guidance into how to play, though. If the first player plays perfectly, she’s compelled to win. This is something which happens in many two-player, symmetric games. A symmetric game is one where either player has the same set of available moves, and can make the same moves with the same results. This proof needs to be tightened up to really hold. But it should convince you, at least, that the first player has an advantage.
So given that, the question becomes why play this game after you’ve decided who’ll go first? The reason you might if you were playing a game is, what, you have something else to do? And maybe you think you’ll make fewer mistakes than your opponent. One approach often used in symmetric games like this is the “pie rule”. The name comes from the story about how to slice a pie so you and your sibling don’t fight over the results. One cuts the pie, the other gets first pick of the slice, and then you fight anyway. In this game, though, one player makes a tentative first move. The other decides whether they will be Player One with that first move made or whether they’ll be Player Two, responding.
There are some neat quirks in the commercial Y games. One is that they don’t actually show hexes, and you don’t put tokens in the middle of hexes. Instead you put tokens on the spots that would be the center of the hex. On the board are lines pointing to the neighbors. This makes the board actually a string of triangles. This is the dual to the hex grid. It shows a set of vertices, and their connections, instead of hexes and their neighbors. Whether you think the hex grid or this dual makes it easier to tell when you’ve connected all three edges is a matter of taste. It does make the edges less jagged all around.
Another is that there will be three vertices that don’t connect to six others. They connect to five others, instead. Their spaces would be pentagons. As I understand the literature on this, this is a concession to game balance. It makes it easier for one side to fend off a path coming from the center.
It has geometric significance, though. A pure hexagonal grid is a structure that tiles the plane. A mostly hexagonal grid, with a couple of pentagons, though? That can tile the sphere. To cover the whole sphere you need something like at least twelve irregular spots. But this? With the three pentagons? That gives you a space that’s topographically equivalent to a hemisphere, or at least a slice of the sphere. If we do imagine the board to be a hemisphere covered, then the result of the handful of pentagon spaces is to make the “pole” closer to the equator.
So as I say the game seems fun enough to play. And it shows off some of the ways that game theorists classify games. And the questions they ask about games. Is the game always won by someone? Does one party have an advantage? Can one party always force a win? It also shows the kinds of approach game theorists can use to answer these questions. This before they consider whether they’d enjoy playing it.
I am excited to say that there’s just the one more time this year that I will realize: it’s Wednesday evening and I’m 1200 words short. Please stop in Thursday when I hope to have the letter Z represented. That, and all of this year’s A-to-Z essays, should appear at this link. And if that isn’t enough, I’ll feature some past essays on Friday and Saturday, and have most of my past A-to-Z essays at this link. Thank you.

 . They’re also dumped on the poor student in calculus, as something about Newton’s binomial coefficient theorem. Which we hear is something really important. In my experience it wasn’t explained why this should rank up there with, like, the differential calculus. (Spoiler: it’s because of polynomials.) But it’s got some great stuff to it.
. They’re also dumped on the poor student in calculus, as something about Newton’s binomial coefficient theorem. Which we hear is something really important. In my experience it wasn’t explained why this should rank up there with, like, the differential calculus. (Spoiler: it’s because of polynomials.) But it’s got some great stuff to it. 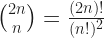
 or 1. If ‘n’ is 1, this number is
or 1. If ‘n’ is 1, this number is  or 2. If ‘n’ is 2, this number is
or 2. If ‘n’ is 2, this number is 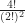 6. If ‘n’ is 3, this number is (sparing the formula) 20. The numbers keep growing. 70, 252, 924, 3432, 12870, and so on.
6. If ‘n’ is 3, this number is (sparing the formula) 20. The numbers keep growing. 70, 252, 924, 3432, 12870, and so on.  is never squarefree as long as ‘n’ is big enough. András Sárközy showed in 1985 that this was true. How big is big enough? … We have a bound, at least, for this theorem. If ‘n’ is larger than the number
is never squarefree as long as ‘n’ is big enough. András Sárközy showed in 1985 that this was true. How big is big enough? … We have a bound, at least, for this theorem. If ‘n’ is larger than the number 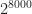 then the corresponding coefficient can’t be squarefree. It might not surprise you that the formulas involved here feature the Riemann Zeta function. That always seems to turn up for questions about large prime numbers.
then the corresponding coefficient can’t be squarefree. It might not surprise you that the formulas involved here feature the Riemann Zeta function. That always seems to turn up for questions about large prime numbers.  . That’s a number something more than 12 million digits long. In 1991 I Vardi proved we had no squarefree central binomial coefficients for ‘n’ greater than 4 and less than
. That’s a number something more than 12 million digits long. In 1991 I Vardi proved we had no squarefree central binomial coefficients for ‘n’ greater than 4 and less than 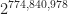 , which is a number about 233 million digits long. And then in 1996 Andrew Granville and Olivier Ramare showed directly that this was so for all ‘n’ larger than 4.
, which is a number about 233 million digits long. And then in 1996 Andrew Granville and Olivier Ramare showed directly that this was so for all ‘n’ larger than 4. 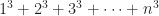 — then it’s true for the next —
— then it’s true for the next —  — is work. But you can get it done.
— is work. But you can get it done. 
 and so on. That’s not wrong. The name we give a number doesn’t matter. But it makes it harder to remember what coefficient matches up with, say, x14.)
and so on. That’s not wrong. The name we give a number doesn’t matter. But it makes it harder to remember what coefficient matches up with, say, x14.) 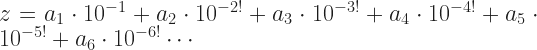
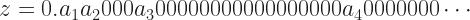
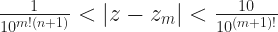
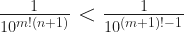
 and
and  . Same old boring fixed points. The cosine is a little more interesting. For that we have
. Same old boring fixed points. The cosine is a little more interesting. For that we have  .
.  ). It creeps into problems that don’t look like fixed points. Calculus students learn of something called the Newton-Raphson Iteration. It finds roots, points where a function f(x) equals zero. Mathematics majors learn of numerical methods to solve ordinary differential equations. The most stable of these are again fixed-point iteration schemes, albeit in disguise.
). It creeps into problems that don’t look like fixed points. Calculus students learn of something called the Newton-Raphson Iteration. It finds roots, points where a function f(x) equals zero. Mathematics majors learn of numerical methods to solve ordinary differential equations. The most stable of these are again fixed-point iteration schemes, albeit in disguise.  . I found it in the paper “Irrationality From The Book,” by Steven J. Miller, David Montague, which was recently posted to arXiv.org.
. I found it in the paper “Irrationality From The Book,” by Steven J. Miller, David Montague, which was recently posted to arXiv.org.
{kind=link}