Today’s topic is another request, this one from a Dina. I’m not sure if this is Dina Yagodich, who’d also suggested using the letter ‘e’ for the number ‘e’. Trusting that it is, Dina Yagodich has a YouTube channel of mathematics videos. They cover topics like how to convert degrees and radians to one another, what the chance of a false positive (or false negative) on a medical test is, ways to solve differential equations, and how to use computer tools like MathXL, TI-83/84 calculators, or Matlab. If I’m mistaken, original-commenter Dina, please let me know and let me know if you have any creative projects that should be mentioned here.

Fermat’s Last Theorem.
It comes to us from number theory. Like many great problems in number theory, it’s easy to understand. If you’ve heard of the Pythagorean Theorem you know, at least, there are triplets of whole numbers so that the first number squared plus the second number squared equals the third number squared. It’s easy to wonder about generalizing. Are there quartets of numbers, so the squares of the first three add up to the square of the fourth? Quintuplets? Sextuplets? … Oh, yes. That’s easy. What about triplets of whole numbers, including negative numbers? Yeah, and that turns out to be boring. Triplets of rational numbers? Turns out to be the same as triplets of whole numbers. Triplets of real-valued numbers? Turns out to be very boring. Triplets of complex-valued numbers? Also none too interesting.
Ah, but, what about a triplet of numbers, only raised to some other power? All three numbers raised to the first power is easy; we call that addition. To the third power, though? … The fourth? Any other whole number power? That’s hard. It’s hard finding, for any given power, a trio of numbers that work, although some come close. I’m informed there was an episode of The Simpsons which included, as a joke, the equation 

For a Fermat-like example, Leonhard Euler conjectured a thing about “Sums of Like Powers”. That for a whole number ‘n’, you need at least n whole numbers-raised-to-an-nth-power to equal something else raised to an n-th power. That is, you need at least three whole numbers raised to the third power to equal some other whole number raised to the third power. At least four whole numbers raised to the fourth power to equal something raised to the fourth power. At least five whole numbers raised to the fifth power to equal some number raised to the fifth power. Euler was wrong, in this case. L J Lander and T R Parkin published, in 1966, the one-paragraph paper Counterexample to Euler’s Conjecture on Sums of Like Powers. 
But Fermat’s hypothesis. Let me put it in symbols. It’s easier than giving everything long, descriptive names. Suppose that the power ‘n’ is a whole number greater than 2. Then there are no three counting numbers ‘a’, ‘b’, and ‘c’ which make true the equation 
He was wrong. No shame in that. He was right about a lot of mathematics, including a lot of stuff that leads into the basics of calculus. And he was right in his feeling that this
For specific values of ‘n’, though? Oh yes, that’s doable. Fermat did it himself for an ‘n’ of 4. Euler, a century later, filed in ‘n’ of 3. Peter Dirichlet, a great name in number theory and analysis, and Joseph-Louis Lagrange, who worked on everything, proved the case of ‘n’ of 5. Dirichlet, in 1832, proved the case for ‘n’ of 14. And there were more partial solutions. You could show that if Fermat’s Last Theorem were ever false, it would have to be false for some prime-number value of ‘n’. That’s great work, answering as it does infinitely many possible cases. It just leaves … infinitely many to go.
And that’s how things went for centuries. I don’t know that every mathematician made some attempt on Fermat’s Last Theorem. But it seems hard to imagine a person could love mathematics enough to spend their lives doing it and not at least take an attempt at it. Nobody ever found it, though. In a 1989 episode of Star Trek: The Next Generation, Captain Picard muses on how eight centuries after Fermat nobody’s proven his theorem. This struck me at the time as too pessimistic. Granted humans were stumped for 400 years. But for 800 years? And stumping everyone in a whole Federation of a thousand worlds? And more than a thousand mathematical traditions? And, for some of these species, tens of thousands of years of recorded history? … Still, there wasn’t much sign of the solving the problem. In 1992 Analog Science Fiction Magazine published a funny short-short story by Ian Randal Strock, “Fermat’s Legacy”. In it, Fermat — jealous of figures like René Descartes and Blaise Pascal who upstaged his mathematical accomplishments — jots down the note. He figures an unsupported claim like that will earn true lasting fame.
So that takes us to 1993, when the world heard about elliptic integrals for the first time. Elliptic curves are neat things. They’re polynomials. They have some nice mathematical properties. People first noticed them in studying how long arcs of ellipses are. (This is why they’re called elliptic curves, even though most of them have nothing to do with any ellipse you’d ever tolerate in your presence.) They look ready to use for encryption. And in 1985, Gerhard Frey noticed something. Suppose you did have, for some ‘n’ bigger than 2, a solution 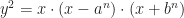
I would like to tell you what it means for an elliptic curve to be modular. But getting to that point would take at least four subsidiary essays. MathWorld has a description of what it means to be modular, and even links to explaining terms like “meromorphic”. It’s getting exotic stuff.
Frey didn’t show whether elliptic curves of this time had to be modular or not. This is normal enough, for mathematicians. You want to find things which are true and interesting. This includes conjectures like this, that if elliptic curves are all modular then Fermat’s Last Theorem has to be true. Frey was working on consequences of the Taniyama-Shimura Conjecture, itself three decades old at that point. Yutaka Taniyama and Goro Shimura had found there seemed to be a link between elliptic curves and these “modular forms”, which are a kind of group. That is, a group-theory thing.
So in fall of 1993 I was taking an advanced, though still undergraduate, course in (not-high-school) algebra at Rutgers. It’s where we learn group theory, after Intro to Algebra introduced us to group theory. Some exciting news came out. This fellow named Andrew Wiles at Princeton had shown an impressive bunch of things. Most important, that the Taniyama-Shimura Conjecture was true for semistable elliptic curves. This includes the kind of elliptic curve Frey made out of solutions to Fermat’s Last Theorem. So the curves based on solutions to Fermat’s Last Theorem would have be modular. But Frey had shown any curves based on solutions to Fermat’s Last Theorem couldn’t be modular. The conclusion: there can’t be any solutions to Fermat’s Last Theorem. Our professor did his best to explain the proof to us. Abstract Algebra was the undergraduate course closest to the stuff Wiles was working on. It wasn’t very close. When you’re still trying to work out what it means for something to be an ideal it’s hard to even follow the setup of the problem. The proof itself was inaccessible.
Which is all right. Wiles’s original proof had some flaws. At least this mathematics major shrugged when that news came down and wondered, well, maybe it’ll be fixed someday. Maybe not. I remembered how exciting cold fusion was for about six weeks, too. But this someday didn’t take long. Wiles, with Richard Taylor, revised the proof and published about a year later. So far as I’m aware, nobody has any serious qualms about the proof.
So does knowing Fermat’s Last Theorem get us anything interesting? … And here is a sad anticlimax. It’s neat to know that
Which is not to say studying it was foolish. This easy-to-understand, hard-to-solve problem certainly attracted talented minds to think about mathematics. Mathematicians found interesting stuff in trying to solve it. Some of it might be slight. I learned that in a Pythagorean triplet — ‘a’, ‘b’, and ‘c’ with 
Kind viewers have tried to retcon Picard’s statement about Fermat’s Last Theorem. They say Picard was really searching for the proof Fermat had, or believed he had. Something using the mathematical techniques available to the early 17th century. Or that follow closely enough from that. The Taniyama-Shimura Conjecture definitely isn’t it. I don’t buy the retcon, but I’m willing to play along for the sake of not causing trouble. I suspect there’s not a proof of the general case that uses anything Fermat could have recognized, or thought he had. That’s all right. The search for a thing can be useful even if the thing doesn’t exist.


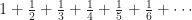 , ending when we get up to one divided by the number of episodes in the season. 25 or 26, for most seasons of Deep Space Nine. 15, from when they counted here. This is the start of the harmonic series.
, ending when we get up to one divided by the number of episodes in the season. 25 or 26, for most seasons of Deep Space Nine. 15, from when they counted here. This is the start of the harmonic series.  , and so on. The “series” is the sum of a sequence, a single number. I agree it seems weird to call a “series” that sum, but it’s the word we’re stuck with. If it helps, consider: when we talk about “a TV series” we usually mean the whole body of work, not individual episodes.) You can pick any number, however tiny you like. I can then respond with the last term in the sequence bigger than your number. Infinitely many terms in the sequence will be smaller than your pick. And yet: you can pick any number you like, however big. And I can take a finite number of terms in this sequence to make a sum bigger than whatever number you liked. The sum will eventually be bigger than 10, bigger than 100, bigger than a googolplex. These two facts are easy to prove, but they seem like they ought to be contradictory. You can see why infinite series are fun and produce much screaming on the part of students.
, and so on. The “series” is the sum of a sequence, a single number. I agree it seems weird to call a “series” that sum, but it’s the word we’re stuck with. If it helps, consider: when we talk about “a TV series” we usually mean the whole body of work, not individual episodes.) You can pick any number, however tiny you like. I can then respond with the last term in the sequence bigger than your number. Infinitely many terms in the sequence will be smaller than your pick. And yet: you can pick any number you like, however big. And I can take a finite number of terms in this sequence to make a sum bigger than whatever number you liked. The sum will eventually be bigger than 10, bigger than 100, bigger than a googolplex. These two facts are easy to prove, but they seem like they ought to be contradictory. You can see why infinite series are fun and produce much screaming on the part of students.  drunk episodes. This is a number a little bigger than 3.318. So, more likely three drunk episodes, four being likely. For the 25-episode seasons (seasons four and seven, if I’m reading this right), we could expect
drunk episodes. This is a number a little bigger than 3.318. So, more likely three drunk episodes, four being likely. For the 25-episode seasons (seasons four and seven, if I’m reading this right), we could expect 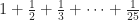 or just over 3.816 drunk episodes. Likely four, maybe three. For the 26-episode seasons (seasons two, five, and six), we could expect
or just over 3.816 drunk episodes. Likely four, maybe three. For the 26-episode seasons (seasons two, five, and six), we could expect 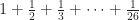 drunk episodes. That’s just over 3.854.
drunk episodes. That’s just over 3.854. 





{kind=link}