Today’s is one of my requested mathematics terms. This one comes to us from group theory, by way of Gaurish, and as ever I’m thankful for the prompt.
Monster Group.
It’s hard to learn from an example. Examples are great, and I wouldn’t try teaching anything subtle without one. Might not even try teaching the obvious without one. But a single example is dangerous. The learner has trouble telling what parts of the example are the general lesson to learn and what parts are just things that happen to be true for that case. Having several examples, of different kinds of things, saves the student. The thing in common to many different examples is the thing to retain.
The mathematics major learns group theory in Introduction To Not That Kind Of Algebra, MAT 351. A group extracts the barest essence of arithmetic: a bunch of things and the ability to add them together. So what’s an example? … Well, the integers do nicely. What’s another example? … Well, the integers modulo two, where the only things are 0 and 1 and we know 1 + 1 equals 0. What’s another example? … The integers modulo three, where the only things are 0 and 1 and 2 and we know 1 + 2 equals 0. How about another? … The integers modulo four? Modulo five?
All true. All, also, basically the same thing. The whole set of integers, or of real numbers, are different. But as finite groups, the integers modulo anything are nice easy to understand groups. They’re known as Cyclic Groups for reasons I’ll explain if asked. But all the Cyclic Groups are kind of the same.
So how about another example? And here we get some good ones. There’s the Permutation Groups. These are fun. You start off with a set of things. You can label them anything you like, but you’re daft if you don’t label them the counting numbers. So, say, the set of things 1, 2, 3, 4, 5. Start with them in that order. A permutation is the swapping of any pair of those things. So swapping, say, the second and fifth things to get the list 1, 5, 3, 4, 2. The collection of all the swaps you can make is the Permutation Group on this set of things. The things in the group are not 1, 2, 3, 4, 5. The things in the permutation group are “swap the second and fifth thing” or “swap the third and first thing” or “swap the fourth and the third thing”. You maybe feel uneasy about this. That’s all right. I suggest playing with this until you feel comfortable because it is a lot of fun to play with. Playing in this case mean writing out all the ways you can swap stuff, which you can always do as a string of swaps of exactly two things.
(Some people may remember an episode of Futurama that involved a brain-swapping machine. Or a body-swapping machine, if you prefer. The gimmick of the episode is that two people could only swap bodies/brains exactly one time. The problem was how to get everybody back in their correct bodies. It turns out to be possible to do, and one of the show’s writers did write a proof of it. It’s shown on-screen for a moment. Many fans were awestruck by an episode of the show inspiring a Mathematical Theorem. They’re overestimating how rare theorems are. But it is fun when real mathematics gets done as a side effect of telling a good joke. Anyway, the theorem fits well in group theory and the study of these permutation groups.)
So the student wanting examples of groups can get the Permutation Group on three elements. Or the Permutation Group on four elements. The Permutation Group on five elements. … You kind of see, this is certainly different from those Cyclic Groups. But they’re all kind of like each other.
An “Alternating Group” is one where all the elements in it are an even number of permutations. So, “swap the second and fifth things” would not be in an alternating group. But “swap the second and fifth things, and swap the fourth and second things” would be. And so the student needing examples can look at the Alternating Group on two elements. Or the Alternating Group on three elements. The Alternating Group on four elements. And so on. It’s slightly different from the Permutation Group. It’s certainly different from the Cyclic Group. But still, if you’ve mastered the Alternating Group on five elements you aren’t going to see the Alternating Group on six elements as all that different.
Cyclic Groups and Alternating Groups have some stuff in common. Permutation Groups not so much and I’m going to leave them in the above paragraph, waving, since they got me to the Alternating Groups I wanted.
One is that they’re finite. At least they can be. I like finite groups. I imagine students like them too. It’s nice having a mathematical thing you can write out in full and know you aren’t missing anything.
The second thing is that they are, or they can be, “simple groups”. That’s … a challenge to explain. This has to do with the structure of the group and the kinds of subgroup you can extract from it. It’s very very loosely and figuratively and do not try to pass this off at your thesis defense kind of like being a prime number. In fact, Cyclic Groups for a prime number of elements are simple groups. So are Alternating Groups on five or more elements.
So we get to wondering: what are the finite simple groups? Turns out they come in four main families. One family is the Cyclic Groups for a prime number of things. One family is the Alternating Groups on five or more things. One family is this collection called the Chevalley Groups. Those are mostly things about projections: the ways to map one set of coordinates into another. We don’t talk about them much in Introduction To Not That Kind Of Algebra. They’re too deep into Geometry for people learning Algebra. The last family is this collection called the Twisted Chevalley Groups, or the Steinberg Groups. And they .. uhm. Well, I never got far enough into Geometry I’m Guessing to understand what they’re for. I’m certain they’re quite useful to people working in the field of order-three automorphisms of the whatever exactly D4 is.
And that’s it. That’s all the families there are. If it’s a finite simple group then it’s one of these. … Unless it isn’t.
Because there are a couple of stragglers. There are a few finite simple groups that don’t fit in any of the four big families. And it really is only a few. I would have expected an infinite number of weird little cases that don’t belong to a family that looks similar. Instead, there are 26. (27 if you decide a particular one of the Steinberg Groups doesn’t really belong in that family. I’m not familiar enough with the case to have an opinion.) Funny number to have turn up. It took ten thousand pages to prove there were just the 26 special cases. I haven’t read them all. (I haven’t read any of the pages. But my Algebra professors at Rutgers were proud to mention their department’s work in tracking down all these cases.)
Some of these cases have some resemblance to one another. But not enough to see them as a family the way the Cyclic Groups are. We bundle all these together in a wastebasket taxon called “the sporadic groups”. The first five of them were worked out in the 1860s. The last of them was worked out in 1980, seven years after its existence was first suspected.
The sporadic groups all have weird sizes. The smallest one, known as M11 (for “Mathieu”, who found it and four of its siblings in the 1860s) has 7,920 things in it. They get enormous soon after that.
The biggest of the sporadic groups, and the last one described, is the Monster Group. It’s known as M. It has a lot of things in it. In particular it’s got 808,017,424,794,512,875,886,459,904,961,710,757,005,754,368,000,000,000 things in it. So, you know, it’s not like we’ve written out everything that’s in it. We’ve just got descriptions of how you would write out everything in it, if you wanted to try. And you can get a good argument going about what it means for a mathematical object to “exist”, or to be “created”. There are something like 1054 things in it. That’s something like a trillion times a trillion times the number of stars in the observable universe. Not just the stars in our galaxy, but all the stars in all the galaxies we could in principle ever see.
It’s one of the rare things for which “Brobdingnagian” is an understatement. Everything about it is mind-boggling, the sort of thing that staggers the imagination more than infinitely large things do. We don’t really think of infinitely large things; we just picture “something big”. A number like that one above is definite, and awesomely big. Just read off the digits of that number; it sounds like what we imagine infinity ought to be.
We can make a chart, called the “character table”, which describes how subsets of the group interact with one another. The character table for the Monster Group is 194 rows tall and 194 columns wide. The Monster Group can be represented as this, I am solemnly assured, logical and beautiful algebraic structure. It’s something like a polyhedron in rather more than three dimensions of space. In particular it needs 196,884 dimensions to show off its particular beauty. I am taking experts’ word for it. I can’t quite imagine more than 196,883 dimensions for a thing.
And it’s a thing full of mystery. This creature of group theory makes us think of the number 196,884. The same 196,884 turns up in number theory, the study of how integers are put together. It’s the first non-boring coefficient in a thing called the j-function. It’s not coincidence. This bit of number theory and this bit of group theory are bound together, but it took some years for anyone to quite understand why.
There are more mysteries. The character table has 194 rows and columns. Each column implies a function. Some of those functions are duplicated; there are 171 distinct ones. But some of the distinct ones it turns out you can find by adding together multiples of others. There are 163 distinct ones. 163 appears again in number theory, in the study of algebraic integers. These are, of course, not integers at all. They’re things that look like complex-valued numbers: some real number plus some (possibly other) real number times the square root of some specified negative number. They’ve got neat properties. Or weird ones.
You know how with integers there’s just one way to factor them? Like, fifteen is equal to three times five and no other set of prime numbers? Algebraic integers don’t work like that. There’s usually multiple ways to do that. There are exceptions, algebraic integers that still have unique factorings. They happen only for a few square roots of negative numbers. The biggest of those negative numbers? Minus 163.
I don’t know if this 163 appearance means something. As I understand the matter, neither does anybody else.
There is some link to the mathematics of string theory. That’s an interesting but controversial and hard-to-experiment-upon model for how the physics of the universe may work. But I don’t know string theory well enough to say what it is or how surprising this should be.
The Monster Group creates a monster essay. I suppose it couldn’t do otherwise. I suppose I can’t adequately describe all its sublime mystery. Dr Mark Ronan has written a fine web page describing much of the Monster Group and the history of our understanding of it. He also has written a book, Symmetry and the Monster, to explain all this in greater depths. I’ve not read the book. But I do mean to, now.
 .
. 

 . That maybe looks a little more computer-y. But I bet you can read that already: “f matches x to y”. Or maybe “f maps x to y”.
. That maybe looks a little more computer-y. But I bet you can read that already: “f matches x to y”. Or maybe “f maps x to y”. 
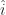 .
. 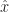 .
. 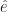 . It’s not something we see on its own. It’s always above some variable.
. It’s not something we see on its own. It’s always above some variable. 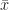 . Maybe
. Maybe  if we must. Must be some number. But what is it? If we can’t measure whatever it is for every single example of our group — the whole population — then we have to make an estimate. We do that by taking a sample, ideally one that isn’t biased in some way. (This is so hard to do, or at least be sure you’ve done.) We can find the mean for this sample, though, because that’s how we picked it. The mean of this sample is probably close to the mean of the whole population. It’s an estimate. So we can write
if we must. Must be some number. But what is it? If we can’t measure whatever it is for every single example of our group — the whole population — then we have to make an estimate. We do that by taking a sample, ideally one that isn’t biased in some way. (This is so hard to do, or at least be sure you’ve done.) We can find the mean for this sample, though, because that’s how we picked it. The mean of this sample is probably close to the mean of the whole population. It’s an estimate. So we can write  .
.  . That sort of thing. (Or if we’re typing, we might put the letter in boldface: x. This was good back before computers let us put in mathematics without giving the typesetters hazard pay.) We don’t always do that. By the time we do a lot of stuff with vectors we don’t always need the reminder. But we will include it if we need a warning. Like if we want to have both
. That sort of thing. (Or if we’re typing, we might put the letter in boldface: x. This was good back before computers let us put in mathematics without giving the typesetters hazard pay.) We don’t always do that. By the time we do a lot of stuff with vectors we don’t always need the reminder. But we will include it if we need a warning. Like if we want to have both  telling us where something is and to use a plain old
telling us where something is and to use a plain old  to tell us how big the vector
to tell us how big the vector 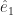 and
and 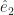 and for that matter
and for that matter 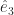 and I bet you have an idea what the next one in the set might be. You might be right. These are basis vectors for normal, Euclidean space, which is why they’re labelled “e”. We have as many of them as we have dimensions of space. We have as many dimensions of space as we need for whatever problem we’re working on. If we need a basis vector and aren’t sure which one, we summon one of the letters used as indices all the time.
and I bet you have an idea what the next one in the set might be. You might be right. These are basis vectors for normal, Euclidean space, which is why they’re labelled “e”. We have as many of them as we have dimensions of space. We have as many dimensions of space as we need for whatever problem we’re working on. If we need a basis vector and aren’t sure which one, we summon one of the letters used as indices all the time.  , say, or
, say, or 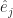 . If we have an n-dimensional space, then we have unit vectors all the way up to
. If we have an n-dimensional space, then we have unit vectors all the way up to  .
.  . OK, that’s just the one number. But we will write numbers like
. OK, that’s just the one number. But we will write numbers like 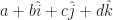 . Here a, b, c, and d are all real numbers. This is kind of sloppy; the pieces of a quaternion aren’t in fact vectors added together. But it is hard not to look at a quaternion and see something pointing in some direction, like the first vectors we ever learn about. And there are some problems in pointing-in-a-direction vectors that quaternions handle so well. (Mostly how to rotate one direction around another axis.) So a bit of vector notation seeps in where it isn’t appropriate.
. Here a, b, c, and d are all real numbers. This is kind of sloppy; the pieces of a quaternion aren’t in fact vectors added together. But it is hard not to look at a quaternion and see something pointing in some direction, like the first vectors we ever learn about. And there are some problems in pointing-in-a-direction vectors that quaternions handle so well. (Mostly how to rotate one direction around another axis.) So a bit of vector notation seeps in where it isn’t appropriate.  . I give you back some other function — say,
. I give you back some other function — say,  . Then I’m acting as an operator.
. Then I’m acting as an operator. 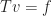 true.
true.  for some ‘v’ that isn’t just zero everywhere.
for some ‘v’ that isn’t just zero everywhere.
