When I first published this I mentioned not knowing why ‘z’ got picked as a variable name. Any letter besides ‘x’ would make sense. As happens when I toss this sort of question out, I haven’t learned anything about why ‘z’ and not, oh, ‘y’ or ‘t’ or even ‘d’. My best guess is that we don’t want to confuse references to the original data with references to the transformed. And while you can write a ‘z’ so badly it looks like an ‘x’, it’s much easier to write a ‘y’ that looks like an ‘x’. I don’t know whether the Preliminary SAT is still a thing.
And we come to the last of the Leap Day 2016 Mathematics A To Z series! Z is a richer letter than x or y, but it’s still not so rich as you might expect. This is why I’m using a term that everybody figured I’d use the last time around, when I went with z-transforms instead.
Z-Score
You get an exam back. You get an 83. Did you do well?
Hard to say. It depends on so much. If you expected to barely pass and maybe get as high as a 70, then you’ve done well. If you took the Preliminary SAT, with a composite score that ranges from 60 to 240, an 83 is catastrophic. If the instructor gave an easy test, you maybe scored right in the middle of the pack. If the instructor sees tests as a way to weed out the undeserving, you maybe had the best score in the class. It’s impossible to say whether you did well without context.
The z-score is a way to provide that context. It draws that context by comparing a single score to all the other values. And underlying that comparison is the assumption that whatever it is we’re measuring fits a pattern. Usually it does. The pattern we suppose stuff we measure will fit is the Normal Distribution. Sometimes it’s called the Standard Distribution. Sometimes it’s called the Standard Normal Distribution, so that you know we mean business. Sometimes it’s called the Gaussian Distribution. I wouldn’t rule out someone writing the Gaussian Normal Distribution. It’s also called the bell curve distribution. As the names suggest by throwing around “normal” and “standard” so much, it shows up everywhere.
A normal distribution means that whatever it is we’re measuring follows some rules. One is that there’s a well-defined arithmetic mean of all the possible results. And that arithmetic mean is the most common value to turn up. That’s called the mode. Also, this arithmetic mean, and mode, is also the median value. There’s as many data points less than it as there are greater than it. Most of the data values are pretty close to the mean/mode/median value. There’s some more as you get farther from this mean. But the number of data values far away from it are pretty tiny. You can, in principle, get a value that’s way far away from the mean, but it’s unlikely.
We call this standard because it might as well be. Measure anything that varies at all. Draw a chart with the horizontal axis all the values you could measure. The vertical axis is how many times each of those values comes up. It’ll be a standard distribution uncannily often. The standard distribution appears when the thing we measure satisfies some quite common conditions. Almost everything satisfies them, or nearly satisfies them. So we see bell curves so often when we plot how frequently data points come up. It’s easy to forget that not everything is a bell curve.
The normal distribution has a mean, and median, and mode, of 0. It’s tidy that way. And it has a standard deviation of exactly 1. The standard deviation is a way of measuring how spread out the bell curve is. About 95 percent of all observed results are less than two standard deviations away from the mean. About 99 percent of all observed results are less than three standard deviations away. 99.9997 percent of all observed results are less than six standard deviations away. That last might sound familiar to those who’ve worked in manufacturing. At least it des once you know that the Greek letter sigma is the common shorthand for a standard deviation. “Six Sigma” is a quality-control approach. It’s meant to make sure one understands all the factors that influence a product and controls them. This is so the product falls outside the design specifications only 0.0003 percent of the time.
This is the normal distribution. It has a standard deviation of 1 and a mean of 0, by definition. And then people using statistics go and muddle the definition. It is always so, with the stuff people actually use. Forgive them. It doesn’t really change the shape of the curve if we scale it, so that the standard deviation is, say, two, or ten, or π, or any positive number. It just changes where the tick marks are on the x-axis of our plot. And it doesn’t really change the shape of the curve if we translate it, adding (or subtracting) some number to it. That makes the mean, oh, 80. Or -15. Or eπ. Or some other number. That just changes what value we write underneath the tick marks on the plot’s x-axis. We can find a scaling and translation of the normal distribution that fits whatever data we’re observing.
When we find the z-score for a particular data point we’re undoing this translation and scaling. We figure out what number on the standard distribution maps onto the original data set’s value. About two-thirds of all data points are going to have z-scores between -1 and 1. About nineteen out of twenty will have z-scores between -2 and 2. About 99 out of 100 will have z-scores between -3 and 3. If we don’t see this, and we have a lot of data points, then that’s suggests our data isn’t normally distributed.
I don’t know why the letter ‘z’ is used for this instead of, say, ‘y’ or ‘w’ or something else. ‘x’ is out, I imagine, because we use that for the original data. And ‘y’ is a natural pick for a second measured variable. z’, I expect, is just far enough from ‘x’ it isn’t needed for some more urgent duty, while being close enough to ‘x’ to suggest it’s some measured thing.
The z-score gives us a way to compare how interesting or unusual scores are. If the exam on which we got an 83 has a mean of, say, 74, and a standard deviation of 5, then we can say this 83 is a pretty solid score. If it has a mean of 78 and a standard deviation of 10, then the score is better-than-average but not exceptional. If the exam has a mean of 70 and a standard deviation of 4, then the score is fantastic. We get to meaningfully compare scores from the measurements of different things. And so it’s one of the tools with which statisticians build their work.





![Caption: Eric had good feelings about his date. It turned out, contrary to what he first thought ... [ Venn Diagram picture of two circles with a good amount of overlap ] ... They actually had quite a lot in common.](https://nebusresearch.files.wordpress.com/2019/03/eric-the-circle_janka_19-march-2019.jpeg)




 for a couple values of j. You want the line that “best” matches that. Fine. In my pinball league case here, j is the whole numbers from 1 to 8.
for a couple values of j. You want the line that “best” matches that. Fine. In my pinball league case here, j is the whole numbers from 1 to 8. 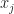 is … just j again. All right, as happens, this is more mechanism than we need for this problem. But there’s problems where it would be useful anyway. And for
is … just j again. All right, as happens, this is more mechanism than we need for this problem. But there’s problems where it would be useful anyway. And for 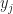 , well, here:
, well, here: 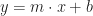 . No idea what ‘m’ and ‘b’ are just yet. But. Calculate for each of the
. No idea what ‘m’ and ‘b’ are just yet. But. Calculate for each of the 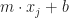 . How far are those from the actual
. How far are those from the actual 

![Bea: 'Aaaah! I forgot to do my maths homework!' Tonus: 'I did mine.' Bea: 'Can I copy yours?' Tonus: 'Of course you can. I didn't know the answers so I drew a picture of a scary dinosaur.' [ Silent penultimate panel. ] Bea: 'Better than nothing.' Tonus: 'Remember the big teeth. Big teeth make it scary.'](https://nebusresearch.files.wordpress.com/2018/04/anthony-blades_bewley_23-april-2018.gif)
![[ Clown Statistician vs Clown mathematician. ] The Clown Statistician holds up a pie chart, ready to throw it. The mathematician holds up a pi symbol, ready to throw it. Corner squirrel's comment: 'There's always room for more pi.'](https://nebusresearch.files.wordpress.com/2018/04/dave-whamond_reality-check_23-april-2018.gif)
![[ With rain delaying (baseball) practice, Kevin Pelwecki expounds on his new favorite subject --- ] Kevin: 'Launch angle! You want the ball coming off the bat at 25 degrees.' Teammate: 'Anyone else notice we're taking math lessons --- from a guy who barely passed geometry?'](https://nebusresearch.files.wordpress.com/2018/04/neal-rubin-rod-whigham_gil-thorp_24-april-2018.gif)





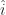 .
. 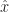 .
. 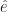 . It’s not something we see on its own. It’s always above some variable.
. It’s not something we see on its own. It’s always above some variable. 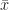 . Maybe
. Maybe  if we must. Must be some number. But what is it? If we can’t measure whatever it is for every single example of our group — the whole population — then we have to make an estimate. We do that by taking a sample, ideally one that isn’t biased in some way. (This is so hard to do, or at least be sure you’ve done.) We can find the mean for this sample, though, because that’s how we picked it. The mean of this sample is probably close to the mean of the whole population. It’s an estimate. So we can write
if we must. Must be some number. But what is it? If we can’t measure whatever it is for every single example of our group — the whole population — then we have to make an estimate. We do that by taking a sample, ideally one that isn’t biased in some way. (This is so hard to do, or at least be sure you’ve done.) We can find the mean for this sample, though, because that’s how we picked it. The mean of this sample is probably close to the mean of the whole population. It’s an estimate. So we can write  .
.  . That sort of thing. (Or if we’re typing, we might put the letter in boldface: x. This was good back before computers let us put in mathematics without giving the typesetters hazard pay.) We don’t always do that. By the time we do a lot of stuff with vectors we don’t always need the reminder. But we will include it if we need a warning. Like if we want to have both
. That sort of thing. (Or if we’re typing, we might put the letter in boldface: x. This was good back before computers let us put in mathematics without giving the typesetters hazard pay.) We don’t always do that. By the time we do a lot of stuff with vectors we don’t always need the reminder. But we will include it if we need a warning. Like if we want to have both  telling us where something is and to use a plain old
telling us where something is and to use a plain old  to tell us how big the vector
to tell us how big the vector 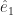 and
and 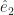 and for that matter
and for that matter 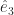 and I bet you have an idea what the next one in the set might be. You might be right. These are basis vectors for normal, Euclidean space, which is why they’re labelled “e”. We have as many of them as we have dimensions of space. We have as many dimensions of space as we need for whatever problem we’re working on. If we need a basis vector and aren’t sure which one, we summon one of the letters used as indices all the time.
and I bet you have an idea what the next one in the set might be. You might be right. These are basis vectors for normal, Euclidean space, which is why they’re labelled “e”. We have as many of them as we have dimensions of space. We have as many dimensions of space as we need for whatever problem we’re working on. If we need a basis vector and aren’t sure which one, we summon one of the letters used as indices all the time.  , say, or
, say, or 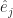 . If we have an n-dimensional space, then we have unit vectors all the way up to
. If we have an n-dimensional space, then we have unit vectors all the way up to  .
.  . OK, that’s just the one number. But we will write numbers like
. OK, that’s just the one number. But we will write numbers like 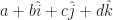 . Here a, b, c, and d are all real numbers. This is kind of sloppy; the pieces of a quaternion aren’t in fact vectors added together. But it is hard not to look at a quaternion and see something pointing in some direction, like the first vectors we ever learn about. And there are some problems in pointing-in-a-direction vectors that quaternions handle so well. (Mostly how to rotate one direction around another axis.) So a bit of vector notation seeps in where it isn’t appropriate.
. Here a, b, c, and d are all real numbers. This is kind of sloppy; the pieces of a quaternion aren’t in fact vectors added together. But it is hard not to look at a quaternion and see something pointing in some direction, like the first vectors we ever learn about. And there are some problems in pointing-in-a-direction vectors that quaternions handle so well. (Mostly how to rotate one direction around another axis.) So a bit of vector notation seeps in where it isn’t appropriate. 









