Okay, so writing “this next essay right away” didn’t come to pass, because all sorts of other things got in the way. But to get back to where we had been: we hoped to figure out which of the players at the local pinball league had most improved over the season. The data I had available. But data is always imperfect. We try to learn anyway.
What data I had was this. Each league night we selected five pinball games. Each player there played those five tables. We recorded their scores. Each player’s standing was based on, for each table, how many other players they beat. If you beat everyone on a particular table, you got 100 points. If you beat all but three people, you got 96 points. If ten people beat you, you got 90 points. And so on. Add together the points earned for all five games of that night. We didn’t play the same games week to week. And not everyone played every single week. These are some of the limits of the data.
My first approach was to look at a linear regression. That is, take a plot where the independent variable is the league night number and the dependent variable is player’s nightly scores. This will almost certainly not be a straight line. There’s an excellent chance it will never touch any of the data points. But there is some line that comes closer than any other line to touching all these data points. What is that line, and what is its slope? And that’s easy to calculate. Well, it’s tedious to calculate. But the formula for it is easy enough to make a computer do. And then it’s easy to look at the slope of the line approximating each player’s performance. The highest slope of their performance line obviously belongs to the best player.
And the answer gotten was that the most improved player — the one whose score increased most, week to week — was a player I’ll call T. The thing is T was already a good player. A great one, really. He’d just been unable to join the league until partway through. So nights that he didn’t play, and so was retroactively given a minimal score for, counted as “terrible early nights”. This made his play look like it was getting better than it was. It’s not just a problem of one person, either. I had missed a night, early on, and that weird outlier case made my league performance look, to this regression, like it was improving pretty well. If we removed the missed nights, my apparent improvement changed to a slight decline. If we pretend that my second-week absence happened on week eight instead, I had a calamitous fall over the season.
And that felt wrong, so I went back to re-think. This is dangerous stuff, by the way. You can fool yourself if you go back and change your methods because your answer looked wrong. But. An important part of finding answers is validating your answer. Getting a wrong-looking answer can be a warning that your method was wrong. This is especially so if you started out unsure how to find what you were looking for.
So what did that first answer, that I didn’t believe, tell me? It told me I needed some better way to handle noisy data. I should tell apart a person who’s steadily doing better week to week and a person who’s just had one lousy night. Or two lousy nights. Or someone who just had a lousy season, but enjoyed one outstanding night where they couldn’t be beaten. Is there a measure of consistency?
And there — well, there kind of is. I’m looking at Pearson’s Correlation Coefficient, also known as Pearson’s r, or r. Karl Pearson is a name you will know if you learn statistics, because he invented just about all of them except the Student T test. Or you will not know if you learn statistics, because we don’t talk much about the history of statistics. (A lot of the development of statistical ideas was done in the late 19th and early 20th century, often by people — like Pearson — who were eugenicists. When we talk about mathematics history we’re more likely to talk about, oh, this fellow published what he learned trying to do quality control at Guinness breweries. We move with embarrassed coughing past oh, this fellow was interested in showing which nationalities were dragging the average down.) I hope you’ll allow me to move on with just some embarrassed coughing about this.
Anyway, Pearson’s ‘r’ is a number between -1 and 1. It reflects how well a line actually describes your data. The closer this ‘r’ is to zero, the less like a line your data really is. And the square of this, r2, has a great, easy physical interpretation. It tells you how much of the variations in your dependent variable — the rankings, here — can be explained by a linear function of the independent variable — the league night, here. The bigger r2 is, the more line-like the original data is. The less its result depends on fluke events.
This is another tedious calculation, yes. Computers. They do great things for statistical study. These told me something unsurprising: r2 for our putative best player, T, was about 0.313. That is, about 31 percent of his score’s change could be attributed to improvement; 69 percent of it was noise, reflecting the missed nights. For me, r2 was about 0.105. That is, 90 percent of the variation in my standing was noise. This suggests by the way that I was playing pretty consistently, week to week, which matched how I felt about my season. And yes, we did have one player whose r2 was 0.000. So he was consistent and about all the change in his week-to-week score reflected noise. (I only looked at three digits past the decimal. That’s more precision than the data could support, though. I wouldn’t be willing to say whether he played more consistently than the person with r2 of 0.005 or the one with 0.012.)
Now, looking at that — ah, here’s something much better. Here’s a player, L, with a Pearson’s r of 0.803. r2 was about 0.645, the highest of anyone. The most nearly linear performance in the league. Only about 35 percent of L’s performance change could be attributed to random noise rather than to a linear change, week-to-week. And that change was the second-highest in the league, too. L’s standing improved by about 5.21 points per league night. Better than anyone but T.
This, then, was my nomination for the most improved player. L had a large positive slope, in looking at ranking-over-time. L also also a high correlation coefficient. This makes the argument that the improvement was consistent and due to something besides L getting luckier later in the season.
Yes, I am fortunate that I didn’t have to decide between someone with a high r2 and mediocre slope versus someone with a mediocre r2 and high slope. Maybe this season. I’ll let you know how it turns out.


 for a couple values of j. You want the line that “best” matches that. Fine. In my pinball league case here, j is the whole numbers from 1 to 8.
for a couple values of j. You want the line that “best” matches that. Fine. In my pinball league case here, j is the whole numbers from 1 to 8. 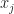 is … just j again. All right, as happens, this is more mechanism than we need for this problem. But there’s problems where it would be useful anyway. And for
is … just j again. All right, as happens, this is more mechanism than we need for this problem. But there’s problems where it would be useful anyway. And for 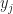 , well, here:
, well, here: 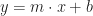 . No idea what ‘m’ and ‘b’ are just yet. But. Calculate for each of the
. No idea what ‘m’ and ‘b’ are just yet. But. Calculate for each of the 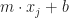 . How far are those from the actual
. How far are those from the actual 








