Back in the day I taught in a Computational Science department, which threw me out to exciting and new-to-me subjects more than once. One quite fun semester I was learning, and teaching, signal processing. This set me up for the triumphant conclusion of my first A-to-Z.
One of the things you can see in my style is mentioning the connotations implied by whether one uses x or z as a variable. Any letter will do, for the use it’s put to. But to use the name ‘z’ suggests an openness to something that ‘x’ doesn’t.
There’s a mention here about stability in algorithms, and the note that we can process data in ways that are stable or are unstable. I don’t mention why one would want or not want stability. Wanting stability hardly seems to need explaining; isn’t that the good option? And, often, yes, we want stable systems because they correct and wipe away error. But there are reasons we might want instability, or at least less stability. Too stable a system will obscure weak trends, or the starts of trends. Your weight flutters day by day in ways that don’t mean much, which is why it’s better to consider a seven-day average. If you took instead a 700-day running average, these meaningless fluctuations would be invisible. But you also would take a year or more to notice whether you were losing or gaining weight. That’s one of the things stability costs.
z-transform.
The z-transform comes to us from signal processing. The signal we take to be a sequence of numbers, all representing something sampled at uniformly spaced times. The temperature at noon. The power being used, second-by-second. The number of customers in the store, once a month. Anything. The sequence of numbers we take to stretch back into the infinitely great past, and to stretch forward into the infinitely distant future. If it doesn’t, then we pad the sequence with zeroes, or some other safe number that we know means “nothing”. (That’s another classic mathematician’s trick.)
It’s convenient to have a name for this sequence. “a” is a good one. The different sampled values are denoted by an index. a0 represents whatever value we have at the “start” of the sample. That might represent the present. That might represent where sampling began. That might represent just some convenient reference point. It’s the equivalent of mileage maker zero; we have to have something be the start.
a1, a2, a3, and so on are the first, second, third, and so on samples after the reference start. a-1, a-2, a-3, and so on are the first, second, third, and so on samples from before the reference start. That might be the last couple of values before the present.
So for example, suppose the temperatures the last several days were 77, 81, 84, 82, 78. Then we would probably represent this as a-4 = 77, a-3 = 81, a-2 = 84, a-1 = 82, a0 = 78. We’ll hope this is Fahrenheit or that we are remotely sensing a temperature.
The z-transform of a sequence of numbers is something that looks a lot like a polynomial, based on these numbers. For this five-day temperature sequence the z-transform would be the polynomial 
I would not be surprised if you protested that this doesn’t merely look like a polynomial but actually is one. You’re right, of course, for this set, where all our samples are from negative (and zero) indices. If we had positive indices then we’d lose the right to call the transform a polynomial. Suppose we trust our weather forecaster completely, and add in a1 = 83 and a2 = 76. Then the z-transform for this set of data would be 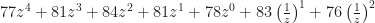
The use of z for these polynomials is basically arbitrary. The main reason to use z instead of x is that we can learn interesting things if we imagine letting z be a complex-valued number. And z carries connotations of “a possibly complex-valued number”, especially if it’s used in ways that suggest we aren’t looking at coordinates in space. It’s not that there’s anything in the symbol x that refuses the possibility of it being complex-valued. It’s just that z appears so often in the study of complex-valued numbers that it reminds a mathematician to think of them.
A sound question you might have is: why do this? And there’s not much advantage in going from a list of temperatures “77, 81, 84, 81, 78, 83, 76” over to a polynomial-like expression
Where this starts to get useful is when we have an infinitely long sequence of numbers to work with. Yes, it does too. It will often turn out that an interesting sequence transforms into a polynomial that itself is equivalent to some easy-to-work-with function. My little temperature example there won’t do it, no. But consider the sequence that’s zero for all negative indices, and 1 for the zero index and all positive indices. This gives us the polynomial-like structure 

Probably you’ll grant that, but still wonder what the point of doing that is. Remember that we started by thinking of signal processing. A processed signal is a matter of transforming your initial signal. By this we mean multiplying your original signal by something, or adding something to it. For example, suppose we want a five-day running average temperature. This we can find by taking one-fifth today’s temperature, a0, and adding to that one-fifth of yesterday’s temperature, a-1, and one-fifth of the day before’s temperature a-2, and one-fifth a-3, and one-fifth a-4.
The effect of processing a signal is equivalent to manipulating its z-transform. By studying properties of the z-transform, such as where its values are zero or where they are imaginary or where they are undefined, we learn things about what the processing is like. We can tell whether the processing is stable — does it keep a small error in the original signal small, or does it magnify it? Does it serve to amplify parts of the signal and not others? Does it dampen unwanted parts of the signal while keeping the main intact?
We can understand how data will be changed by understanding the z-transform of the way we manipulate it. That z-transform turns a signal-processing idea into a complex-valued function. And we have a lot of tools for studying complex-valued functions. So we become able to say a lot about the processing. And that is what the z-transform gets us.
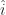 , and the direction of the y-axis as
, and the direction of the y-axis as 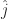 . The direction of the z-axis if needed gets written
. The direction of the z-axis if needed gets written  . The circumflex there indicates two things. First is that the thing underneath it is a vector. Second is that it’s a vector one unit long. A vector might have any length, including zero. It’s convenient to make some mention when it’s a nice one unit long.
. The circumflex there indicates two things. First is that the thing underneath it is a vector. Second is that it’s a vector one unit long. A vector might have any length, including zero. It’s convenient to make some mention when it’s a nice one unit long. 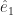 , and the y-axis as the vector
, and the y-axis as the vector 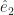 , and so on. This method offers several advantages. One is that we can talk about the vector
, and so on. This method offers several advantages. One is that we can talk about the vector 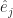 , that is, some particular direction without pinning down just which one. That’s the equivalent of writing “x” or “y” for a number we don’t want to commit ourselves to just yet. Another is that we can talk about axes going off in two, or three, or four, or more directions without having to pin down how many there are. And then we don’t have to think of what to call them. x- and y- and z-axes make sense. w-axis sounds a little odd but some might accept it. v-axis? u-axis? Nobody wants that, trust me.
, that is, some particular direction without pinning down just which one. That’s the equivalent of writing “x” or “y” for a number we don’t want to commit ourselves to just yet. Another is that we can talk about axes going off in two, or three, or four, or more directions without having to pin down how many there are. And then we don’t have to think of what to call them. x- and y- and z-axes make sense. w-axis sounds a little odd but some might accept it. v-axis? u-axis? Nobody wants that, trust me.  so that the y-axis is the direction
so that the y-axis is the direction  is perpendicular to the function
is perpendicular to the function  . And when we want to study a more complicated function we can separate the part that’s in the “direction” of f(x) from the part that’s in the “direction” of g(x). We can treat functions, even functions we don’t know, as if they were locations in space. And we can study and even solve for the different parts of the function as if we were pinning down the north-south and the east-west movements of a thing.
. And when we want to study a more complicated function we can separate the part that’s in the “direction” of f(x) from the part that’s in the “direction” of g(x). We can treat functions, even functions we don’t know, as if they were locations in space. And we can study and even solve for the different parts of the function as if we were pinning down the north-south and the east-west movements of a thing. 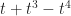 contains enough information to draw one knot as opposed to all the others that might exist. (In this case it’s a very simple knot, one known as the right-hand trefoil knot. A trefoil knot is a knot with a trefoil-like pattern.) Indeed, it’s possible to describe knots with polynomials that let you distinguish between a knot and its mirror-image reflection.
contains enough information to draw one knot as opposed to all the others that might exist. (In this case it’s a very simple knot, one known as the right-hand trefoil knot. A trefoil knot is a knot with a trefoil-like pattern.) Indeed, it’s possible to describe knots with polynomials that let you distinguish between a knot and its mirror-image reflection. 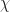 ), or the letter I, or the number 1 put in some kind of fancy heavy font, with the D as a subscript so we know which characteristic function it is.
), or the letter I, or the number 1 put in some kind of fancy heavy font, with the D as a subscript so we know which characteristic function it is.  is
is 