I’m fortunate this week to have another topic suggested again by Mr Wu, blogger and Singaporean mathematics tutor. It’s a big field, so forgive me not explaining the entire subject.
Analysis.
Analysis is about proving why the rest of mathematics works. It’s a hard field. My experience, a typical one, included crashing against real analysis as an undergraduate and again as a graduate student. It turns out mathematics works by throwing a lot of  symbols around.
symbols around.
Let me give an example. If you read pop mathematics blogs you know about the number represented by  . You’ve seen proofs, some of them even convincing, that this number equals 1. Not a tiny bit less than 1, but exactly 1. Here’s a real-analysis treatment. And — I may regret this — I recommend you don’t read it. Not closely, at least. Instead, look at its shape. Look at the words and symbols as graphic design elements, and trust that what I say is not nonsense. Resume reading after the horizontal rule.
. You’ve seen proofs, some of them even convincing, that this number equals 1. Not a tiny bit less than 1, but exactly 1. Here’s a real-analysis treatment. And — I may regret this — I recommend you don’t read it. Not closely, at least. Instead, look at its shape. Look at the words and symbols as graphic design elements, and trust that what I say is not nonsense. Resume reading after the horizontal rule.
It’s convenient to have a name for the number . I’ll call that  , for “repeating”. 1 we’ll call 1. I think you’ll grant that whatever r is, it can’t be more than 1. I hope you’ll accept that if the difference between 1 and r is zero, then r equals 1. So what is the difference between 1 and r?
, for “repeating”. 1 we’ll call 1. I think you’ll grant that whatever r is, it can’t be more than 1. I hope you’ll accept that if the difference between 1 and r is zero, then r equals 1. So what is the difference between 1 and r?
Give me some number . It has to be a positive number. The implication in the letter is that it’s a small number. This isn’t actually required in general. We expect it. We feel surprise and offense if it’s ever not the case.
I can show that the difference between 1 and r is less than . I know there is some smallest counting number N so that  . For example, say is 0.125. Then we can let N = 1, and
. For example, say is 0.125. Then we can let N = 1, and 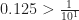 . Or suppose is 0.00625. But then if N = 3,
. Or suppose is 0.00625. But then if N = 3,  . (If is bigger than 1, let N = 1.) Now we have to ask why I want this N.
. (If is bigger than 1, let N = 1.) Now we have to ask why I want this N.
Whatever the value of r is, I know that it is more than 0.9. And that it is more than 0.99. And that it is more than 0.999. In fact, it’s more than the number you get by truncating r after any whole number N of digits. Let me call  the number you get by truncating r after N digits. So,
the number you get by truncating r after N digits. So,  and
and 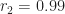 and
and  and so on.
and so on.
Since 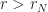 , it has to be true that
, it has to be true that  . And since we know what is, we can say exactly what
. And since we know what is, we can say exactly what 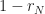 is. It's
is. It's 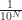 . And we picked N so that
. And we picked N so that  . So
. So 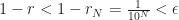 . But all we know of is that it's a positive number. It can be any positive number. So
. But all we know of is that it's a positive number. It can be any positive number. So 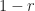 has to be smaller than each and every positive number. The biggest number that’s smaller than every positive number is zero. So the difference between 1 and r must be zero and so they must be equal.
has to be smaller than each and every positive number. The biggest number that’s smaller than every positive number is zero. So the difference between 1 and r must be zero and so they must be equal.
That is a compelling argument. Granted, it compels much the way your older brother kneeling on your chest and pressing your head into the ground compels. But this argument gives the flavor of what much of analysis is like.
For one, it is fussy, leaning to technical. You see why the subject has the reputation of driving off all but the most intent mathematics majors. If you get comfortable with this sort of argument it’s hard to notice anymore.
For another, the argument shows that the difference between two things is less than every positive number. Therefore the difference is zero and so the things are equal. This is one of mathematics’ most important tricks. And another point, there’s a lot of talk about . And about finding differences that are, it usually turns out, smaller than some . (As an undergraduate I found something wasteful in how the differences were so often so much less than . We can’t exhaust the small numbers, though. It still feels uneconomic.)
Something this misses is another trick, though. That’s adding zero. I couldn’t think of a good way to use that here. What we often get is the need to show that, say, function 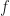 and function
and function  are equal. That is, that they are less than apart. What we can often do is show that is close to some related function, which let me call
are equal. That is, that they are less than apart. What we can often do is show that is close to some related function, which let me call  .
.
I know what you’re suspecting: must be a polynomial. Good thought! Although in my experience, it’s actually more likely to be a piecewise constant function. That is, it’s some number, eg, “2”, for part of the domain, and then “2.5” in some other region, with no transition between them. Some other values, even values not starting with “2”, in other parts of the domain. Usually this is easier to prove stuff about than even polynomials are.
But get back to 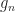 . It’s got the same deal as , some approximation easier to prove stuff about. Then we want to show that is close to some . And then show that is close to . So — watch this trick. Or, again, watch the shape of this trick. Read again after the horizontal rule.
. It’s got the same deal as , some approximation easier to prove stuff about. Then we want to show that is close to some . And then show that is close to . So — watch this trick. Or, again, watch the shape of this trick. Read again after the horizontal rule.
The difference  is equal to
is equal to  since adding zero, that is, adding the number
since adding zero, that is, adding the number 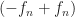 , can’t change a quantity. And is equal to
, can’t change a quantity. And is equal to  . Same reason:
. Same reason:  is zero. So:
is zero. So:

Now we use the “triangle inequality”. If a, b, and c are the lengths of a triangle’s sides, the sum of any two of those numbers is larger than the third. And that tells us:

And then if you can show that 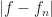 is less than
is less than  ? And that
? And that  is also ? And you see where this is going for
is also ? And you see where this is going for 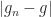 ? Then you’ve shown that
? Then you’ve shown that  . With luck, each of these little pieces is something you can prove.
. With luck, each of these little pieces is something you can prove.
Don’t worry about what all this means. It’s meant to give a flavor of what you do in an analysis course. It looks hard, but most of that is because it’s a different sort of work than you’d done before. If you hadn’t seen the adding-zero and triangle-inequality tricks? I don’t know how long you’d need to imagine them.
There are other tricks too. An old reliable one is showing that one thing is bounded by the other. That is, that  . You use this trick all the time because if you can also show that
. You use this trick all the time because if you can also show that 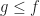 , then those two have to be equal.
, then those two have to be equal.
The good thing — and there is good — is that once you get the hang of these tricks analysis starts to come together. And even get easier. The first course you take as a mathematics major is real analysis, all about functions of real numbers. The next course in this track is complex analysis, about functions of complex-valued numbers. And it is easy. Compared to what comes before, yes. But also on its own. Every theorem in complex analysis named after Augustin-Louis Cauchy. They all show that the integral of your function, calculated along a closed loop, is zero. I exaggerate by .
In grad school, if you make it, you get to functional analysis, which examines functions on functions and other abstractions like that. This, too, is easy, possibly because all the basic approaches you’ve seen several courses over. Or it feels easy after all that mucking around with the real numbers.
This is not the entirety of explaining how mathematics works. Since all these proofs depend on how numbers work, we need to show how numbers work. How logic works. But those are subjects we can leave for grad school, for someone who’s survived this gauntlet.
I hope to return in a week with a fresh A-to-Z essay. This week’s essay, and all the essays for the Little Mathematics A-to-Z, should be at this link. And all this year’s essays, and all A-to-Z essays from past years, should be at this link. Thank you once more for reading.
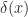 . It’s equal to zero everywhere, except where
. It’s equal to zero everywhere, except where  is zero. When
is zero. When 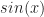 or
or 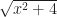 being functions. Many will classify it as a distribution instead. But it is so useful, for a particular kind of problem, that it’s impossible to throw away.
being functions. Many will classify it as a distribution instead. But it is so useful, for a particular kind of problem, that it’s impossible to throw away. 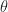 . And there’s how fast the stick is changing,
. And there’s how fast the stick is changing,  . You can draw these axes; I recommend
. You can draw these axes; I recommend  to mean we find whatever number, added to b, gives us 0. Then we add that to a. We do this pretty often, so it’s convenient to have a name for it. The word “subtraction” appears in English from about 1400. It grew from the Latin for “taking away”. By about 1425 the word has its mathematical meaning. I imagine this wasn’t too radical a linguistic evolution.
to mean we find whatever number, added to b, gives us 0. Then we add that to a. We do this pretty often, so it’s convenient to have a name for it. The word “subtraction” appears in English from about 1400. It grew from the Latin for “taking away”. By about 1425 the word has its mathematical meaning. I imagine this wasn’t too radical a linguistic evolution.
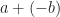 , where
, where  is the additive inverse of
is the additive inverse of  .
.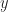 . It depends on a whole range of variables, which we describe as a vector
. It depends on a whole range of variables, which we describe as a vector  . And we have constraints. Each of these is an inequality; we can represent that as demanding some functions of these variables be at most some numbers. We can bundle those functions together as a matrix called
. And we have constraints. Each of these is an inequality; we can represent that as demanding some functions of these variables be at most some numbers. We can bundle those functions together as a matrix called 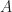 . We can bundle those maximum numbers together as a vector called
. We can bundle those maximum numbers together as a vector called  . So the problem is finding
. So the problem is finding  . Also, we demand that none of these values be smaller than some minimum we might as well call 0. The range of all the possible values of these variables is a space. These constraints chop up that space, into a shape. Into a convex shape, of course, or this paragraph wouldn’t belong in this essay. If you need to be convinced of this, imagine taking a wedge of cheese and hacking away slices all the way through it. How do you cut a cave or a tunnel in it?
. Also, we demand that none of these values be smaller than some minimum we might as well call 0. The range of all the possible values of these variables is a space. These constraints chop up that space, into a shape. Into a convex shape, of course, or this paragraph wouldn’t belong in this essay. If you need to be convinced of this, imagine taking a wedge of cheese and hacking away slices all the way through it. How do you cut a cave or a tunnel in it? , my angle might be 30 degrees. Or -30 degrees. Or 390 degrees. Or 330 degrees. You may protest there’s no difference between a 30 degree and a 390 degree angle. I agree those angles point in the same direction. But a gear rotated 390 degrees has done something that a gear rotated 30 degrees hasn’t. If all I know is where the dot I’ve put on the gear is, how can I know how much it’s rotated?
, my angle might be 30 degrees. Or -30 degrees. Or 390 degrees. Or 330 degrees. You may protest there’s no difference between a 30 degree and a 390 degree angle. I agree those angles point in the same direction. But a gear rotated 390 degrees has done something that a gear rotated 30 degrees hasn’t. If all I know is where the dot I’ve put on the gear is, how can I know how much it’s rotated?  to mean anything when
to mean anything when  (a typical circle) into a function without some work. We have to write either
(a typical circle) into a function without some work. We have to write either 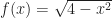 or
or 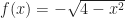 , breaking the circle into two halves. The same happens for hyperbolas, though, with
, breaking the circle into two halves. The same happens for hyperbolas, though, with  (a typical hyperbola) turning into
(a typical hyperbola) turning into  or
or  .
.  or even
or even 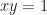 . But it’s the shape we see when we draw
. But it’s the shape we see when we draw  , rotated. Or a rotation of one we see when we draw
, rotated. Or a rotation of one we see when we draw 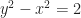 . The equations of rotated shapes are annoying. We do enough of them for ellipses and parabolas and hyperbolas to meet the course requirement. But they point out how the hyperbola is a more normal construct than we fear.
. The equations of rotated shapes are annoying. We do enough of them for ellipses and parabolas and hyperbolas to meet the course requirement. But they point out how the hyperbola is a more normal construct than we fear. 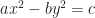 for some constant numbers a, b, and c. (If a, b, and c are all positive, this is a hyperbola opening horizontally. If a and b are positive and c negative, this is a hyperbola opening vertically.) An equation describing an ellipse, similarly with its axes horizontal or vertical looks like
for some constant numbers a, b, and c. (If a, b, and c are all positive, this is a hyperbola opening horizontally. If a and b are positive and c negative, this is a hyperbola opening vertically.) An equation describing an ellipse, similarly with its axes horizontal or vertical looks like 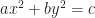 . (These are shapes centered on the origin. They can have other centers, which make the equations harder but not more enlightening.) The equations have very similar shapes. Mathematics trains us to suspect things with similar shapes have similar properties. That change from a plus to a minus seems too important to ignore, and yet …
. (These are shapes centered on the origin. They can have other centers, which make the equations harder but not more enlightening.) The equations have very similar shapes. Mathematics trains us to suspect things with similar shapes have similar properties. That change from a plus to a minus seems too important to ignore, and yet …  , for some real number t, where
, for some real number t, where 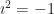 . You haven’t missed a step; I’m summoning this from nowhere. (Let’s not think about how to draw a point with an imaginary coordinate.) Then
. You haven’t missed a step; I’m summoning this from nowhere. (Let’s not think about how to draw a point with an imaginary coordinate.) Then 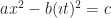 which is
which is  . And despite the weird letters, that’s a circle. By the same supposition we could go from
. And despite the weird letters, that’s a circle. By the same supposition we could go from 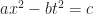 , a hyperbola.
, a hyperbola.  . (The angle
. (The angle  to the origin to the point (1, 0).)
to the origin to the point (1, 0).)  .
. 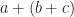 is the same thing as
is the same thing as 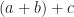 . So it multiplication:
. So it multiplication:  is the same thing as
is the same thing as  .
. 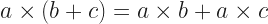
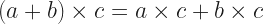
 is always
is always  , whatever
, whatever 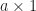 is always
is always 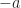 so that
so that  is the additive identity. Multiplication? Even if we have a unit ring, there’s not always a reciprocal. The integers are a unit ring. But there are only two integers that have an integer multiplicative inverse, something you can multiply them by to get 1. If your unit ring does have a multiplicative inverse, this is called a division algebra. Rational numbers, for example, are a division algebra.
is the additive identity. Multiplication? Even if we have a unit ring, there’s not always a reciprocal. The integers are a unit ring. But there are only two integers that have an integer multiplicative inverse, something you can multiply them by to get 1. If your unit ring does have a multiplicative inverse, this is called a division algebra. Rational numbers, for example, are a division algebra.  , because I need some name. Then of all the things in the world, we know this:
, because I need some name. Then of all the things in the world, we know this: 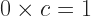
 for some element
for some element 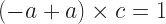

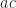 is, nor what its inverse
is, nor what its inverse  is. But I know its sum is zero. And so
is. But I know its sum is zero. And so 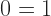
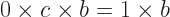
 ,
,  and regular multiplication. It’s a nice example of a “cyclic group”. We can represent the whole thing as multiplying a single element together:
and regular multiplication. It’s a nice example of a “cyclic group”. We can represent the whole thing as multiplying a single element together: 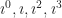 . We can think of
. We can think of 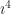 but that’s got the same value as
but that’s got the same value as  . Or
. Or  , which has the same value as
, which has the same value as  . With a little ingenuity we can even think of what we might mean by, say,
. With a little ingenuity we can even think of what we might mean by, say, 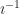 and realize it has to be the same quantity as
and realize it has to be the same quantity as  . Or
. Or 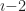 which has to equal
which has to equal  . You see the cycle.
. You see the cycle.  . This is a common name for “an element and we don’t care what it is”. It has nothing to do
. This is a common name for “an element and we don’t care what it is”. It has nothing to do 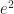 to mean
to mean 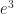 to mean
to mean  . They multiply together the way we might multiply x raised to powers.
. They multiply together the way we might multiply x raised to powers.  is
is  , and
, and  is
is 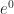 , and
, and  is
is  and so on.
and so on.  is
is 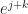 , where j and k are integers. Do we even need to write the e? Why not just write the j and k in a normal-size typeface? Is there a difference between cyclic-group multiplication and regular old addition of integers?
, where j and k are integers. Do we even need to write the e? Why not just write the j and k in a normal-size typeface? Is there a difference between cyclic-group multiplication and regular old addition of integers? 


 correctly. It is, correctly,
correctly. It is, correctly, 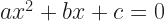
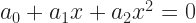
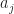 mean we can’t run out of letters to be coefficients. Setting the subscripts and powers to keep increasing lets us write this out neatly.
mean we can’t run out of letters to be coefficients. Setting the subscripts and powers to keep increasing lets us write this out neatly. 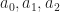 if you’d rather — are all real-valued numbers. Then the quadratic equation has to hav two solutions. There can be two real-valued solutions. There can be one real-valued solution, counted twice for reasons that make sense but are too much a digression for me to justify here. There can be two complex-valued solutions. We can infer the usefulness of imaginary and complex-valued numbers by finding solutions to the quadratic equation.
if you’d rather — are all real-valued numbers. Then the quadratic equation has to hav two solutions. There can be two real-valued solutions. There can be one real-valued solution, counted twice for reasons that make sense but are too much a digression for me to justify here. There can be two complex-valued solutions. We can infer the usefulness of imaginary and complex-valued numbers by finding solutions to the quadratic equation.  . You’ll notice the product of the two solutions is
. You’ll notice the product of the two solutions is  . You’ll glance back at those ancient Babylonian tablets. This seems interesting, but little more than that. It’s a lead, though. Similar formulas exist for the sum of the solutions for a cubic, for a quartic, for other polynomials. Also for the sum of products of pairs of these solutions. Or the sum of products of triplets of these solutions. Or the product of all these solutions. These are known as Vieta’s Formulas, after the 16th-century mathematician François Viète. (This by way of his Latinized, academic’sona, name, Franciscus Vieta.) This gives us a way to rewrite the original polynomial as a set of polynomials in several variables. What’s interesting is the set of polynomials have symmetries. They all look like, oh, “xy + yz + zx”. No one variable gets used in a way distinguishable from the others.
. You’ll glance back at those ancient Babylonian tablets. This seems interesting, but little more than that. It’s a lead, though. Similar formulas exist for the sum of the solutions for a cubic, for a quartic, for other polynomials. Also for the sum of products of pairs of these solutions. Or the sum of products of triplets of these solutions. Or the product of all these solutions. These are known as Vieta’s Formulas, after the 16th-century mathematician François Viète. (This by way of his Latinized, academic’sona, name, Franciscus Vieta.) This gives us a way to rewrite the original polynomial as a set of polynomials in several variables. What’s interesting is the set of polynomials have symmetries. They all look like, oh, “xy + yz + zx”. No one variable gets used in a way distinguishable from the others. 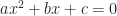 bit. Make a function, instead, something that matches numbers (real, complex, what have you) to numbers (the same). Its rule: any x in the domain matches to the number
bit. Make a function, instead, something that matches numbers (real, complex, what have you) to numbers (the same). Its rule: any x in the domain matches to the number 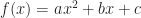 in the range. We can make a picture that represents this. Set Cartesian coordinates — the x and y coordinates that people think of as the default — on a surface. Then highlight all the points with coordinates (x, y) which make true the equation
in the range. We can make a picture that represents this. Set Cartesian coordinates — the x and y coordinates that people think of as the default — on a surface. Then highlight all the points with coordinates (x, y) which make true the equation  . This traces out a particular shape, the parabola.
. This traces out a particular shape, the parabola. 

{kind=link}