Ring.
Early on in her undergraduate career a mathematics major will take a class called Algebra. Actually, Introduction to Algebra is more likely, but another Algebra will follow. She will have to explain to her friends and parents that no, it’s not more of that stuff they didn’t understand in high school about expanding binomial terms and finding quadratic equations. The class is the study of constructs that work much like numbers do, but that aren’t necessarily numbers.
The first structure studied is the group. That’s made of two components. One is a set of elements. There might be infinitely many of them — the real numbers, say, or the whole numbers. Or there might be finitely many — the whole numbers from 0 up to 11, or even just the numbers 0 and 1. The other component is an operation that works like addition. What we mean by “works like addition” is that you can take two of the things in the set, “add” them together, and get something else that’s in the set. It has to be associative: something plus the sum of two other things has to equal the sum of the first two things plus the third thing. That is, 1 + (2 + 3) is the same as (1 + 2) + 3.
Also, by the rules of what makes a group, the addition has to commute. First thing plus second thing has to be the same as second thing plus first thing. That is, 1 + 2 has the same value as 2 + 1 does. Furthermore, there has to be something called the additive identity. It works like zero does in ordinary arithmetic. Anything plus the additive identity is that original thing again. And finally, everything in the group has something that’s its additive inverse. The thing plus the additive inverse is the additive identity, our zero.
If you’re lost, that’s all right. A mathematics major spends as much as four weeks in Intro to Algebra feeling lost here. But this is an example. Suppose we have a group made up of the elements 0, 1, 2, and 3. 0 will be the additive identity: 0 plus anything is that original thing. So 1 plus 0 is 1. 1 plus 1 is 2. 1 plus 2 will be 3. 1 plus 3 will be … well, make that 0 again. 2 plus 0 is 2. 2 plus 1 will be 3. 2 plus 2 will be 0. 2 plus 3 will be 1. 3 plus 0 will be 3. 3 plus 1 will be 0. 3 plus 2 will be 1. 3 plus 3 will be 2. Plus will look like a very strange word at this point.
All the elements in this have an additive inverse. Add 3 to 1 and you get 0. Add 2 to 2 and you get 0. Add 1 to 3 and you get 0. And, yes, add 0 to 0 and you get 0. This means you get to do subtraction just as well as you get to do addition.
We’re halfway there. A “ring”, introduced just as the mathematics major has got the hang of groups, is a group with a second operation. Besides being a collection of elements and an addition-like operation, a ring also has a multiplication-like operation. It doesn’t have to do much, as a multiplication. It has to be associative. That is, something times the product of two other things has to be the same as the product of the first two things times the third. You’ve seen that, though. 1 x (2 x 3) is the same as (1 x 2) x 3. And it has to distribute: something times the sum of two other things has to be the same as the sum of the something times the first thing and the something times the second. That is, 2 x (3 + 4) is the same as 2 x 3 plus 2 x 4.
For example, the group we had before, 0 times anything will be 0. 1 times anything will be what we started with: 1 times 0 is 0, 1 times 1 is 1, 1 times 2 is 2, and 1 times 3 is 3. 2 times 0 is 0, 2 times 1 is 2, 2 times 2 will be 0 again, and 2 times 3 will be 2 again. 3 times 0 is 0, 3 times 1 is 3, 3 times 2 is 2, and 3 times 3 is 1. Believe it or not, this all works out. And “times” doesn’t get to look nearly so weird as “plus” does.
And that’s all you need: a collection of things, an operation that looks a bit like addition, and an operation that looks even more vaguely like multiplication.
Now the controversy. How much does something have to look like multiplication? Some people insist that a ring has to have a multiplicative identity, something that works like 1. The ring I described has one, but one could imagine a ring that hasn’t, such as the even numbers and ordinary addition and multiplication. People who want rings to have multiplicative identity sometimes use “rng” to speak — well, write — of rings that haven’t.
Some people want rings to have multiplicative inverses. That is, anything except zero has something you can multiply it by to get 1. The little ring I built there hasn’t got one, because there’s nothing you can multiply 2 by to get 1. Some insist on multiplication commuting, that 2 times 3 equals 3 times 2.
Who’s right? It depends what you want to do. Everybody agrees that a ring has to have elements, and addition, and multiplication, and that the multiplication has to distribute across addition. The rest depends on the author, and the tradition the author works in. Mathematical constructs are things humans find interesting to study. The details of how they’re made will depend on what work we want to do.
If a mathematician wishes to make clear that she expects a ring to have multiplication that commutes and to have a multiplicative identity she can say so. She would write that something is a commutative ring with identity. Or the context may make things clear. If you’re not sure, then you can suppose she uses the definition of “ring” that was in the textbook from her Intro to Algebra class sophomore year.
It may seem strange to think that mathematicians don’t all agree on what a ring is. After all, don’t mathematicians deal in universal, eternal truths? … And they do; things that are proven by rigorous deduction are inarguably true. But the parts of these truths that are interesting are a matter of human judgement. We choose the bunches of ideas that are convenient to work with, and give names to those. That’s much of what makes this glossary an interesting project.
 . (z1 is the same as z. z0 is the same as the number “1”. I wrote it this way to make the pattern more clear.)
. (z1 is the same as z. z0 is the same as the number “1”. I wrote it this way to make the pattern more clear.) 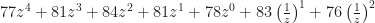 . You’d probably agree that’s not a polynomial, although it looks a lot like one.
. You’d probably agree that’s not a polynomial, although it looks a lot like one.  . And that turns out to be the same as
. And that turns out to be the same as  . That’s much shorter to write down, at least.
. That’s much shorter to write down, at least. 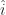 , and the direction of the y-axis as
, and the direction of the y-axis as 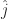 . The direction of the z-axis if needed gets written
. The direction of the z-axis if needed gets written  . The circumflex there indicates two things. First is that the thing underneath it is a vector. Second is that it’s a vector one unit long. A vector might have any length, including zero. It’s convenient to make some mention when it’s a nice one unit long.
. The circumflex there indicates two things. First is that the thing underneath it is a vector. Second is that it’s a vector one unit long. A vector might have any length, including zero. It’s convenient to make some mention when it’s a nice one unit long. 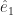 , and the y-axis as the vector
, and the y-axis as the vector 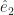 , and so on. This method offers several advantages. One is that we can talk about the vector
, and so on. This method offers several advantages. One is that we can talk about the vector 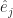 , that is, some particular direction without pinning down just which one. That’s the equivalent of writing “x” or “y” for a number we don’t want to commit ourselves to just yet. Another is that we can talk about axes going off in two, or three, or four, or more directions without having to pin down how many there are. And then we don’t have to think of what to call them. x- and y- and z-axes make sense. w-axis sounds a little odd but some might accept it. v-axis? u-axis? Nobody wants that, trust me.
, that is, some particular direction without pinning down just which one. That’s the equivalent of writing “x” or “y” for a number we don’t want to commit ourselves to just yet. Another is that we can talk about axes going off in two, or three, or four, or more directions without having to pin down how many there are. And then we don’t have to think of what to call them. x- and y- and z-axes make sense. w-axis sounds a little odd but some might accept it. v-axis? u-axis? Nobody wants that, trust me.  so that the y-axis is the direction
so that the y-axis is the direction  is perpendicular to the function
is perpendicular to the function  . And when we want to study a more complicated function we can separate the part that’s in the “direction” of f(x) from the part that’s in the “direction” of g(x). We can treat functions, even functions we don’t know, as if they were locations in space. And we can study and even solve for the different parts of the function as if we were pinning down the north-south and the east-west movements of a thing.
. And when we want to study a more complicated function we can separate the part that’s in the “direction” of f(x) from the part that’s in the “direction” of g(x). We can treat functions, even functions we don’t know, as if they were locations in space. And we can study and even solve for the different parts of the function as if we were pinning down the north-south and the east-west movements of a thing. 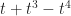 contains enough information to draw one knot as opposed to all the others that might exist. (In this case it’s a very simple knot, one known as the right-hand trefoil knot. A trefoil knot is a knot with a trefoil-like pattern.) Indeed, it’s possible to describe knots with polynomials that let you distinguish between a knot and its mirror-image reflection.
contains enough information to draw one knot as opposed to all the others that might exist. (In this case it’s a very simple knot, one known as the right-hand trefoil knot. A trefoil knot is a knot with a trefoil-like pattern.) Indeed, it’s possible to describe knots with polynomials that let you distinguish between a knot and its mirror-image reflection. 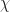 ), or the letter I, or the number 1 put in some kind of fancy heavy font, with the D as a subscript so we know which characteristic function it is.
), or the letter I, or the number 1 put in some kind of fancy heavy font, with the D as a subscript so we know which characteristic function it is.  is
is 