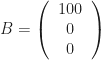For early 2016 — dubbed “Leap Day 2016” as that’s when it started — I got a request to explain orthogonal. I went in a different direction, although not completely different. This essay does get a bit more into specifics of how mathematicians use the idea, like, showing some calculations and such. I put in a casual description of vectors here. For book publication I’d want to rewrite that to be clearer that, like, ordered sets of numbers are just one (very common) way to represent vectors.
Jacob Kanev had requested “orthogonal” for this glossary. I’d be happy to oblige. But I used the word in last summer’s Mathematics A To Z. And I admit I’m tempted to just reprint that essay, since it would save some needed time. But I can do something more.
Orthonormal.
“Orthogonal” is another word for “perpendicular”. Mathematicians use it for reasons I’m not precisely sure of. My belief is that it’s because “perpendicular” sounds like we’re talking about directions. And we want to extend the idea to things that aren’t necessarily directions. As majors, mathematicians learn orthogonality for vectors, things pointing in different directions. Then we extend it to other ideas. To functions, particularly, but we can also define it for spaces and for other stuff.
I was vague, last summer, about how we do that. We do it by creating a function called the “inner product”. That takes in two of whatever things we’re measuring and gives us a real number. If the inner product of two things is zero, then the two things are orthogonal.
The first example mathematics majors learn of this, before they even hear the words “inner product”, are dot products. These are for vectors, ordered sets of numbers. The dot product we find by matching up numbers in the corresponding slots for the two vectors, multiplying them together, and then adding up the products. For example. Give me the vector with values (1, 2, 3), and the other vector with values (-6, 5, -4). The inner product will be 1 times -6 (which is -6) plus 2 times 5 (which is 10) plus 3 times -4 (which is -12). So that’s -6 + 10 – 12 or -8.
So those vectors aren’t orthogonal. But how about the vectors (1, -1, 0) and (0, 0, 1)? Their dot product is 1 times 0 (which is 0) plus -1 times 0 (which is 0) plus 0 times 1 (which is 0). The vectors are perpendicular. And if you tried drawing this you’d see, yeah, they are. The first vector we’d draw as being inside a flat plane, and the second vector as pointing up, through that plane, like a thumbtack.
So that’s orthogonal. What about this orthonormal stuff?
Well … the inner product can tell us something besides orthogonality. What happens if we take the inner product of a vector with itself? Say, (1, 2, 3) with itself? That’s going to be 1 times 1 (which is 1) plus 2 times 2 (4, according to rumor) plus 3 times 3 (which is 9). That’s 14, a tidy sum, although, so what?
The inner product of (-6, 5, -4) with itself? Oh, that’s some ugly numbers. Let’s skip it. How about the inner product of (1, -1, 0) with itself? That’ll be 1 times 1 (which is 1) plus -1 times -1 (which is positive 1) plus 0 times 0 (which is 0). That adds up to 2. And now, wait a minute. This might be something.
Start from somewhere. Move 1 unit to the east. (Don’t care what the unit is. Inches, kilometers, astronomical units, anything.) Then move -1 units to the north, or like normal people would say, 1 unit o the south. How far are you from the starting point? … Well, you’re the square root of 2 units away.
Now imagine starting from somewhere and moving 1 unit east, and then 2 units north, and then 3 units straight up, because you found a convenient elevator. How far are you from the starting point? This may take a moment of fiddling around with the Pythagorean theorem. But you’re the square root of 14 units away.
And what the heck, (0, 0, 1). The inner product of that with itself is 0 times 0 (which is zero) plus 0 times 0 (still zero) plus 1 times 1 (which is 1). That adds up to 1. And, yeah, if we go one unit straight up, we’re one unit away from where we started.
The inner product of a vector with itself gives us the square of the vector’s length. At least if we aren’t using some freak definition of inner products and lengths and vectors. And this is great! It means we can talk about the length — maybe better to say the size — of things that maybe don’t have obvious sizes.
Some stuff will have convenient sizes. For example, they’ll have size 1. The vector (0, 0, 1) was one such. So is (1, 0, 0). And you can think of another example easily. Yes, it’s 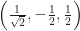
So by “orthonormal” we mean a collection of things that are orthogonal to each other, and that themselves are all of size 1. It’s a description of both what things are by themselves and how they relate to one another. A thing can’t be orthonormal by itself, for the same reason a line can’t be perpendicular to nothing in particular. But a pair of things might be orthogonal, and they might be the right length to be orthonormal too.
Why do this? Well, the same reasons we always do this. We can impose something like direction onto a problem. We might be able to break up a problem into simpler problems, one in each direction. We might at least be able to simplify the ways different directions are entangled. We might be able to write a problem’s solution as the sum of solutions to a standard set of representative simple problems. This one turns up all the time. And an orthogonal set of something is often a really good choice of a standard set of representative problems.
This sort of thing turns up a lot when solving differential equations. And those often turn up when we want to describe things that happen in the real world. So a good number of mathematicians develop a habit of looking for orthonormal sets.

 is the velocity. If we want to emphasize we think of vectors,
is the velocity. If we want to emphasize we think of vectors,  is the position and
is the position and  the velocity.
the velocity.  , or if we want to emphasize its vector nature,
, or if we want to emphasize its vector nature,  . Why a name besides the good enough
. Why a name besides the good enough  , also known as
, also known as  . Or, if we’re sure we won’t lose a ‘ mark,
. Or, if we’re sure we won’t lose a ‘ mark,  . Once we are comfortable thinking of how position changes in time we can think of other changes. Velocity’s change in time we call acceleration. This is also a vector, more abstract than position or velocity. Multiply the acceleration by the mass of the thing accelerating and we have a vector called the “force”. That, we at least feel we understand, and can work with.
. Once we are comfortable thinking of how position changes in time we can think of other changes. Velocity’s change in time we call acceleration. This is also a vector, more abstract than position or velocity. Multiply the acceleration by the mass of the thing accelerating and we have a vector called the “force”. That, we at least feel we understand, and can work with.  , where n is some big enough number like 4.
, where n is some big enough number like 4.  . The superscript-T there, “transposition”, lets us use the tools of matrix algebra. This vector describes a point in phase space. Phase space is the collection of all the physically possible positions and velocities for the system.
. The superscript-T there, “transposition”, lets us use the tools of matrix algebra. This vector describes a point in phase space. Phase space is the collection of all the physically possible positions and velocities for the system.  , or,
, or, 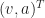 . This acceleration itself depends on, normally, the positions and velocities. So we can describe this as
. This acceleration itself depends on, normally, the positions and velocities. So we can describe this as  for some function
for some function 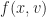 . You are surely impressed with this symbol-shuffling. You are less sure why this bother.
. You are surely impressed with this symbol-shuffling. You are less sure why this bother. 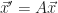 . Or approximate our problem as a matrix problem. This lets us bring in linear algebra tools, and that’s worthwhile.
. Or approximate our problem as a matrix problem. This lets us bring in linear algebra tools, and that’s worthwhile.  . Most of them extend to
. Most of them extend to  . The result is a classic mathematician’s trick. We can recast a problem as one we have better tools to solve.
. The result is a classic mathematician’s trick. We can recast a problem as one we have better tools to solve. 
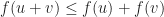 . This is a famous rule, called the triangle inequality. You know how in a triangle, the sum of the lengths of any two legs is greater than the length of the third leg? That’s the rule at work here.
. This is a famous rule, called the triangle inequality. You know how in a triangle, the sum of the lengths of any two legs is greater than the length of the third leg? That’s the rule at work here.  . This doesn’t have so snappy a name. Sorry. It’s something about being homogeneous, at least.
. This doesn’t have so snappy a name. Sorry. It’s something about being homogeneous, at least. 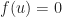 then u has to be the additive identity, the vector that works like zero does.
then u has to be the additive identity, the vector that works like zero does.  . Take the absolute value of each of these
. Take the absolute value of each of these  terms. Then … you have choices. You could take those absolute values and add them up. That’s the L1 polynomial norm. Take those absolute values and square them, then add those squares, and take the square root of that sum. That’s the L2 norm. Take the largest absolute value of any of these coefficients. That’s the L∞ norm.
terms. Then … you have choices. You could take those absolute values and add them up. That’s the L1 polynomial norm. Take those absolute values and square them, then add those squares, and take the square root of that sum. That’s the L2 norm. Take the largest absolute value of any of these coefficients. That’s the L∞ norm. 


 . This is the kind of equation you’ll see all the time in group theory. It’s an important field of mathematics, the one studying sets that work like arithmetic does. This starts with groups, which have a set of things and a binary operation between those things. Think of it as either addition or multiplication. You notice that
. This is the kind of equation you’ll see all the time in group theory. It’s an important field of mathematics, the one studying sets that work like arithmetic does. This starts with groups, which have a set of things and a binary operation between those things. Think of it as either addition or multiplication. You notice that  already looks like multiplication. ‘g’ and ‘h’ serve, for group theory, the roles that ‘x’ and ‘y’ do in (high school) algebra. ‘x’ and ‘y’ mean some number, whose value we might or might not care about. Similarly, ‘g’ and ‘h’ are some elements, things in the set for our group. We might or might not care which ones they are.
already looks like multiplication. ‘g’ and ‘h’ serve, for group theory, the roles that ‘x’ and ‘y’ do in (high school) algebra. ‘x’ and ‘y’ mean some number, whose value we might or might not care about. Similarly, ‘g’ and ‘h’ are some elements, things in the set for our group. We might or might not care which ones they are.  means the identity element, the thing which won’t change the value of the other partner in an operation. The thing that works like zero for addition, or like one for multiplication. And
means the identity element, the thing which won’t change the value of the other partner in an operation. The thing that works like zero for addition, or like one for multiplication. And  means the inverse of
means the inverse of  : the thing which, added (or multiplied) to
: the thing which, added (or multiplied) to  . The union symbol, the U there, speaks of set theory. It means to form a new set, one that has all the elements in the set called X or the set called Y or both. The straight vertical lines flanking these set names or descriptions are how we describe taking the norm, finding the size, of a set. This is ordinarily how many things are inside the set. If the sets X and Y have no elements in common, then the size of the union of X and Y will be the size of the set X plus the size of the set Y.
. The union symbol, the U there, speaks of set theory. It means to form a new set, one that has all the elements in the set called X or the set called Y or both. The straight vertical lines flanking these set names or descriptions are how we describe taking the norm, finding the size, of a set. This is ordinarily how many things are inside the set. If the sets X and Y have no elements in common, then the size of the union of X and Y will be the size of the set X plus the size of the set Y.  has the form of the “mapping” way to define a function. I just don’t understand what the rule here means. The final line,
has the form of the “mapping” way to define a function. I just don’t understand what the rule here means. The final line,  , first … well, this sort of e-raised-to-the-minus-something-squared form turns up all the time. But second, to end a bit of work with an exclamation point really captures the surprise and joy of having reached a goal. Mathematicians take delight in their work, like you’d expect.
, first … well, this sort of e-raised-to-the-minus-something-squared form turns up all the time. But second, to end a bit of work with an exclamation point really captures the surprise and joy of having reached a goal. Mathematicians take delight in their work, like you’d expect. 
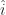 .
. 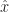 .
. 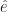 . It’s not something we see on its own. It’s always above some variable.
. It’s not something we see on its own. It’s always above some variable. 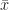 . Maybe
. Maybe  if we must. Must be some number. But what is it? If we can’t measure whatever it is for every single example of our group — the whole population — then we have to make an estimate. We do that by taking a sample, ideally one that isn’t biased in some way. (This is so hard to do, or at least be sure you’ve done.) We can find the mean for this sample, though, because that’s how we picked it. The mean of this sample is probably close to the mean of the whole population. It’s an estimate. So we can write
if we must. Must be some number. But what is it? If we can’t measure whatever it is for every single example of our group — the whole population — then we have to make an estimate. We do that by taking a sample, ideally one that isn’t biased in some way. (This is so hard to do, or at least be sure you’ve done.) We can find the mean for this sample, though, because that’s how we picked it. The mean of this sample is probably close to the mean of the whole population. It’s an estimate. So we can write  . That sort of thing. (Or if we’re typing, we might put the letter in boldface: x. This was good back before computers let us put in mathematics without giving the typesetters hazard pay.) We don’t always do that. By the time we do a lot of stuff with vectors we don’t always need the reminder. But we will include it if we need a warning. Like if we want to have both
. That sort of thing. (Or if we’re typing, we might put the letter in boldface: x. This was good back before computers let us put in mathematics without giving the typesetters hazard pay.) We don’t always do that. By the time we do a lot of stuff with vectors we don’t always need the reminder. But we will include it if we need a warning. Like if we want to have both  telling us where something is and to use a plain old
telling us where something is and to use a plain old  to tell us how big the vector
to tell us how big the vector 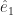 and
and 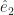 and for that matter
and for that matter 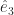 and I bet you have an idea what the next one in the set might be. You might be right. These are basis vectors for normal, Euclidean space, which is why they’re labelled “e”. We have as many of them as we have dimensions of space. We have as many dimensions of space as we need for whatever problem we’re working on. If we need a basis vector and aren’t sure which one, we summon one of the letters used as indices all the time.
and I bet you have an idea what the next one in the set might be. You might be right. These are basis vectors for normal, Euclidean space, which is why they’re labelled “e”. We have as many of them as we have dimensions of space. We have as many dimensions of space as we need for whatever problem we’re working on. If we need a basis vector and aren’t sure which one, we summon one of the letters used as indices all the time.  , say, or
, say, or 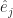 . If we have an n-dimensional space, then we have unit vectors all the way up to
. If we have an n-dimensional space, then we have unit vectors all the way up to  .
.  . OK, that’s just the one number. But we will write numbers like
. OK, that’s just the one number. But we will write numbers like 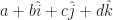 . Here a, b, c, and d are all real numbers. This is kind of sloppy; the pieces of a quaternion aren’t in fact vectors added together. But it is hard not to look at a quaternion and see something pointing in some direction, like the first vectors we ever learn about. And there are some problems in pointing-in-a-direction vectors that quaternions handle so well. (Mostly how to rotate one direction around another axis.) So a bit of vector notation seeps in where it isn’t appropriate.
. Here a, b, c, and d are all real numbers. This is kind of sloppy; the pieces of a quaternion aren’t in fact vectors added together. But it is hard not to look at a quaternion and see something pointing in some direction, like the first vectors we ever learn about. And there are some problems in pointing-in-a-direction vectors that quaternions handle so well. (Mostly how to rotate one direction around another axis.) So a bit of vector notation seeps in where it isn’t appropriate. 
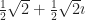 will do. (So will another number.) So I shelved the project.
will do. (So will another number.) So I shelved the project. 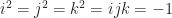
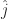 . The direction of the z-axis if needed gets written
. The direction of the z-axis if needed gets written  . The circumflex there indicates two things. First is that the thing underneath it is a vector. Second is that it’s a vector one unit long. A vector might have any length, including zero. It’s convenient to make some mention when it’s a nice one unit long.
. The circumflex there indicates two things. First is that the thing underneath it is a vector. Second is that it’s a vector one unit long. A vector might have any length, including zero. It’s convenient to make some mention when it’s a nice one unit long.  so that the y-axis is the direction
so that the y-axis is the direction